Rootkit学习(一)
简介&内核理解
“A rootkit is a collection of computer software, typically malicious, designed to enable access to a computer or an area of its software that is not otherwise allowed (for example, to an unauthorized user) and often masks its existence or the existence of other software.”
Rootkit 是一组计算机软件,通常是恶意软件,旨在访问计算机或其软件的某个区域(例如,未经授权的用户),并且通常会掩盖其自身或其他软件的存在。
在内核Rootkit中,编写的代码将通过编写的内核模块以内核级权限运行,其核心技术是函数挂钩(function hooking)
这会在内存中找到需要劫持的内核函数(例如列出目录、进程通信等关键操作);然后实现自定义的恶意版本,同时保留原始函数的副本,以维持系统正常功能;接着通过修改内存中的函数指针或代码段,将内核的执行流程重定向到恶意函数,而系统仍能“正常”运行
涉及到开发环境和编译内核模块,建议先更新
基于Ubuntu 20.04
1 | sudo apt update |
这里有一个简单的源代码来帮助我们理解内核模块,来自TheXcellerator
1 |
|
前面包含了一些模块相关的基本定义,主要是__init初始化函数和__exit清理函数,用于模块加载和卸载的使用,并用module_init和module_exit去注册
紧接着我们需要一个用于编译Linux内核模块的Makefile文件(注意缩进)
1 | obj-m += 1.o |
obj-m这个特殊变量去指定要编译为可加载模块的目标文件(注意名字要对应,+=表示追加到变量中)all:代表默认的构建目标,切换到内核构建目录进行编译模块clean:用于清理一些编译生成的文件
1 | 编译模块:make 或 make all |
而后我们看见1.ko(Kernel Object)的内核模块文件,并加载模块
1 | sudo insmod 1.ko |

查看内核信息
1 | modinfo 1.ko |
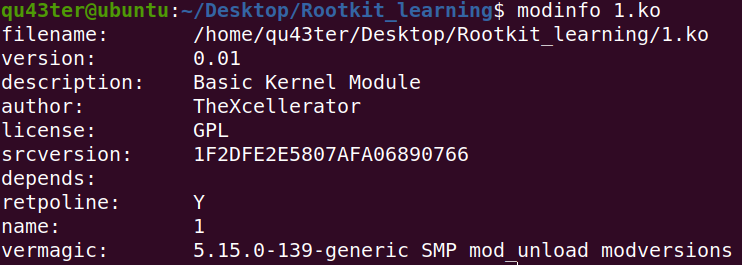
查看内核日志
1 | dmesg |

卸载模块
1 | sudo rmmod 1 |

Ftrace和函数挂钩
我们前面说到Rootkit的本质就是函数劫持,很重要的原理就是函数挂钩,其危害性在于我们可以挂钩系统调用函数
所谓系统调用(System Call),可以理解为用户空间程序与内核空间进行交互的核心接口,其本质是权限边界突破:通过Ring 0-3分级保护,Linux只用Ring 0内核态和Ring 3用户态
如果我们能够干预这些函数,那就有希望提权攻击主要目标,常见的系统调用函数
1 | open() 打开/创建文件 |
用户态空间的系统调用
普通用户调用系统函数的流程是通过int 0x80(x86传统)或syscall/sysenter(x64现代)指令触发软中断,陷入内核态
可以看到上面的调用表中每个系统调用对应着唯一的编号(需要存入寄存器中),我们以sys_write为例,通过man 2 write查找这个系统调用
1 | ssize_t write(int fd, const void *buf, size_t count); |
需要提供三个参数:fd文件描述符,buf 用于存储读取数据的缓冲区,count 读取的字节数
这三个参数按规则存入指定寄存器
| Name | rax | rdi | rsi | rdx |
|---|---|---|---|---|
sys_write |
0x01 |
unsigned int fd |
const char __user *buf |
size_t count |
现代汇编示例:
1 | // 用户态调用write()的底层过程 |
1 | 用户态 → 寄存器传参 → syscall指令 |
内核态空间对系统调用的处理
- 传统方式(x86_64内核 < 4.17.0)
在传统方式下,这种调用会很直接
1 | 用户态 → 寄存器传参 → syscall指令 → 内核入口 → 直接使用寄存器参数 |
通过内核函数原型直接反映参数列表
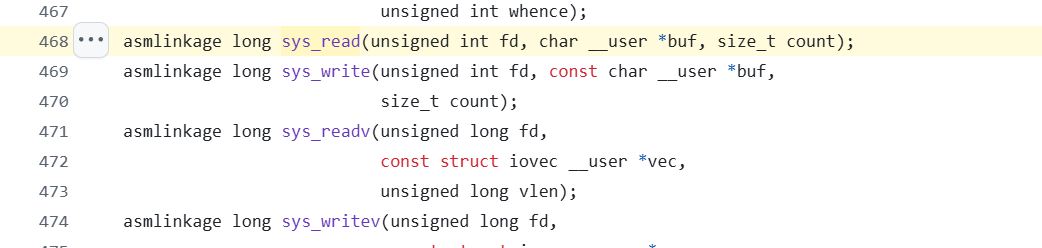
此时对于Rootkit编写会相对容易,因为系统调用的参数传递是透明且易于操作的,能直接模拟原始函数声明来创建钩子,从而实现对参数的控制或修改
- 新方式(x86_64内核 ≥ 4.17.0)
1 | 用户态 → 寄存器传参 → syscall指令 → 内核入口 → 保存寄存器到pt_regs → 通过结构体指针访问参数 |
所有寄存器值被保存到一个名为pt_regs结构体中,系统调用函数统一变为
1 | asmlinkage long sys_write(const struct pt_regs *regs); |
我们编写钩子函数时,需要以这种方式处理参数,手动从结构体提取
1 | int fd = regs->di; // 原rdi寄存器 |
函数钩子
我们尝试拦截sys_mkdir,将目录信息打印在内核日志中
1 |
|
这里做了内核版本的兼容性处理,正如我们上文所说,不同版本中的内核处理系统调用是不一样的
最后都统一用了原函数调用orig_mkdir()
而这里只是主逻辑,还缺少了必要的模块初始化和退出函数,这里我们需要用到钩子函数来做支撑。其中我们需要理解的是钩子钩住了哪些东西,因此我们需要建立一个hook数组中来存储
1 | static struct ftrace_hook hooks[] = { |
这个HOOK宏包括:内核函数的名称,编写的钩子函数,保存原始系统调用的地址
然后我们在初始化和退出阶段分别调用相关函数,整体流程是:
1 | 1.rootkit_init() 被调用 |
当系统调用mkdir时,内核准备执行sys_mkdir,ftrace机制触发 ,调用fh_ftrace_thunk(),并修改regs->ip重定向到我们自定义的hook_mkdir()
其实整体就是一个劫持的过程,基于我们已有的权限,从内核态去做一些我们想要做的事情,这个hook有点像一个“中间件”,在这之间作为一个载体罢了(感觉有点Java动态代理的意思)
一些问题
内核版本更新导致的ftrace API兼容性问题,kallsyms_lookup_name 函数在较新的Linux内核版本(5.7+)中不再导出给内核模块使用,xcellerator也在他的文章有所提及,因此需要一些变动,具体是
-
ftrace_func_t函数签名变更:新版本内核中使用struct ftrace_regs *而不是struct pt_regs * -
FTRACE_OPS_FL_RECURSION_SAFE标志已被移除 -
寄存器访问更新:在
fh_ftrace_thunk函数内部,通过regs->regs.ip而不是regs->ip来访问指令指针寄存器 -
kallsyms_lookup_name函数在较新的Linux内核版本(5.7+)中不再导出给内核模块使用。这需要我们使用替代方法来获取内核符号地址,包含#include <linux/kprobes.h>以使用kprobe功能,并新增lookup_name函数来替代1
2
3
4
5
6
7
8
9
10
11
12static unsigned long lookup_name(const char *name)
{
struct kprobe kp = {
.symbol_name = name
};
unsigned long retval;
if (register_kprobe(&kp) < 0) return 0;
retval = (unsigned long) kp.addr;
unregister_kprobe(&kp);
return retval;
}
更新后的ftrace_helper.h可以看看我的GitHub仓库
之后我们就可以进行编译了
1 | sudo insmod evil_mkdir.ko |
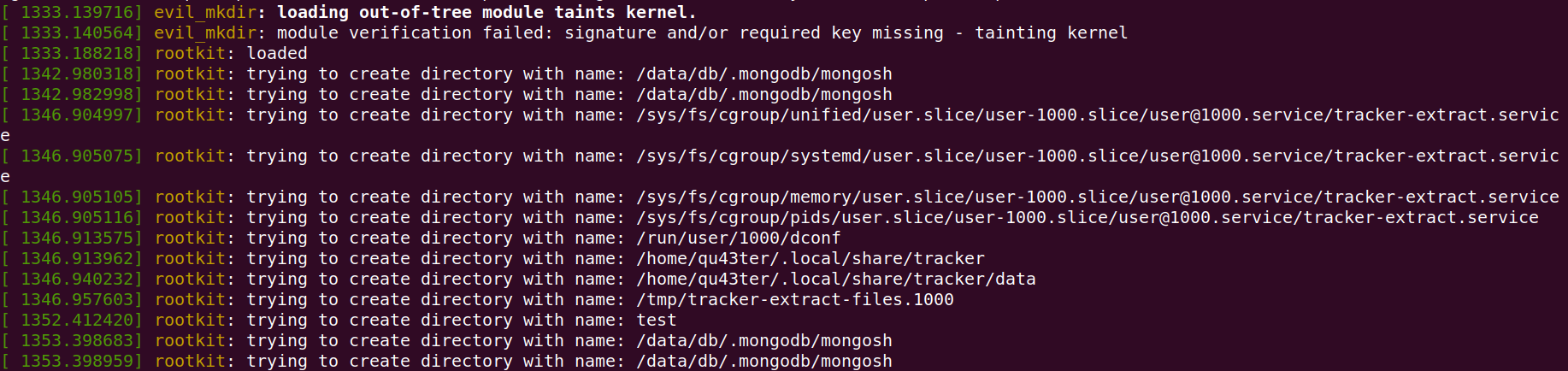
成功劫持,这样来看Rootkit本质就是要在用户态空间暴露的函数去编写一些钩子钩住他,做我们想要做的事情,不一定是系统调用,也有可能是其它对我们有用的函数
参考文章:



